Please Don't Write Your Own MCP Authorization Code
Table of Contents
I’ve been writing software long enough to know that authentication and authorization is where good intentions go to die. It’s complex, it’s boring, and it’s absolutely critical. So when Anthropic, and specifically their Model Context Protocol team shipped their 2025-06-18 specification with a major auth overhaul, I was delighted that we’re one step closer to making it actually palatable for your average engineer that doesn’t care about the ins and outs of auth flows.
So what’s the big news? Anthropic embraced Protected Resource Metadata (PRM) documents for protected MCP servers. Think of it as a business card for your MCP server that says “Hey, if you want to talk to me, here’s where you need to get permission first.”
Architecturally, this is actually brilliant. Instead of every MCP server reinventing the auth wheel, you have a clean separation of concerns: the Authorization Server (often attached to an identity provider, like Entra ID or Okta) handles the messy business of verifying who you are, while your Resource Server (the MCP server) focuses on what it was designed for to begin with (spoiler alert - it’s not auth). The MCP server publishes a simple JSON document that points clients to the right “bouncer” (i.e., the Authorization Server).
But here’s the thing that everyone gets wrong: just because the spec exists doesn’t mean you should implement it yourself.
The wrong way vs. the right way #
Here’s what 90% of developers will do: they’ll crack their knuckles, read the spec, fire up their favorite IDE, add a dependency on their framework du jour, and start building OAuth flows from scratch. They’ll spend weeks wrestling with token caching and validation, refresh logic, and edge cases that make them question their career choices. But maybe they’ll finally get the auth flows to work. What a relief.
Don’t be that developer.
Authentication and authorization is very likely not your core competency unless you work on it as a full-time job. Your MCP server exists to do something useful with AI models, not to become yet another half-baked identity provider.
When I look at the problem space, I think that most of the time the right approach is to use a reverse proxy or API gateway. Let someone else’s battle-tested infrastructure handle the gnarly auth stuff while your code stays blissfully unaware of JWT expiration times and PKCE flows.
If you’re in the Microsoft ecosystem, the combo of Azure API Management (also commonly referred to as APIM) and Azure Functions is practically cheating. Your MCP server becomes a simple function that does exactly one thing well, while APIM sits in front handling all the security functionality.
Configuration over code #
Remember when we used to write five hundred lines of boilerplate just to parse some basic XML? Yeah, good times. Authentication and authorization has been in that same dark age for too long - acquiring tokens and handling their lifetime has not been the definition of “fun” for anyone in the past decade, so why should MCP make it that way?
The beautiful thing about the gateway-based approach I called out above is that auth is not defined in your traditional code at all - it’s all encapsulated in configuration. We’re talking about API Management policies that handle both the PRM document serving and the entire auth flow with Microsoft Entra ID.
No custom middleware. No hand-rolled JWT validation. No “Let me just add this OAuth library and hope it doesn’t have any CVEs.” Just a declarative policy that tells APIM exactly what to do.
What’s the deal with the new flow? #
Alright, enough theory. Let’s see what we’re actually talking about. Here’s what a PRM document looks like in practice, straight from RFC 9728:
{
"resource": "https://your-mcp-server.azure-api.net/",
"authorization_servers": [
"https://login.microsoftonline.com/common/v2.0"
],
"scopes_supported": [
"https://your-mcp-server.azure-api.net/.default"
],
"bearer_methods_supported": [
"header"
]
}
That’s it. Four fields of JSON that tell any MCP client exactly how to authenticate with your server. The client fetches this document, discovers that it needs to talk to Microsoft Entra ID for tokens, gets the appropriate bearer token, and includes it in the Authorization header when making requests.
Your APIM policy serves this document at the well-known endpoint /.well-known/oauth-protected-resource and handles all the token validation behind the scenes. Your actual MCP server code never sees any of this complexity.
But what about security? #
I can already hear the security-conscious developers going: “Great, but who’s storing these tokens? What about token caching? What happens if someone intercepts my JWT?”
Here’s the beautiful part: you don’t have to worry about any of that.
Azure API Management handles server-side token storage and caching automatically. When a client presents a bearer token, APIM validates it against Microsoft Entra ID, caches the validation result for performance, and only forwards the request to your MCP server if the token is valid.
Your server never sees the raw tokens unless it absolutely needs them (e.g., for authorization policy decisions or for downstream On-Behalf-Of flows). Your server never has to implement token storage. Your server never has to worry about token expiration or refresh logic. The MCP client and APIM are doing all the heavy lifting for you.
If you’re worried about token interception, you’re already using HTTPS everywhere (right?), and the tokens themselves are time-limited JWTs that can’t be used outside their intended scope.
And, as the new spec requires, clients will also snap to RFC 8707, which means that a resource parameter will be in use at all times when talking to authorization servers. This will further constrain tokens to their expected destinations.
How do I deploy this? #
Want to see it in action? There’s are two samples you should check out. First, if you are a Python developer, click on the button below:
Check out the codeIf you are prefer .NET, you can use this button instead:
Check out the codeYou can deploy both samples with Azure Developer CLI. All you need to do is run azd up from the root of the sample directory - you’ll have it running in the cloud in minutes. The policies that are auto-deployed are doing all the heavy lifting—making your server MCP spec-compliant without you writing a single line of authentication code.
A PRM-specific policy looks like this:
<!--
Azure API Management Policy for Protected Resource Metadata (RFC 9728)
This policy returns Protected Resource Metadata information for OAuth 2.0 protected resources.
It provides clients with information about the authorization servers, supported methods, and scopes.
Note: Authentication is disabled for this endpoint to allow anonymous access.
-->
<policies>
<inbound>
<!-- Return Protected Resource Metadata according to RFC 9728 -->
<return-response>
<set-status code="200" reason="OK" />
<set-header name="Content-Type" exists-action="override">
<value>application/json</value>
</set-header>
<set-header name="Cache-Control" exists-action="override">
<value>public, max-age=3600</value>
</set-header>
<set-body>@{
return JsonConvert.SerializeObject(new {
resource = "{{APIMGatewayURL}}",
authorization_servers = new[] {
$"{{APIMGatewayURL}}"
},
bearer_methods_supported = new[] {
"header"
},
scopes_supported = new[] {
"https://graph.microsoft.com/.default", "openid"
}
});
}</set-body>
</return-response>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Not bad at all in terms of effort to define this. And deploying all of this takes less than a few minutes.
azd CLI.What about cost and performance? #
Fair questions. Azure API Management isn’t free, and adding another network hop introduces latency. Here’s the quick back-of-the-napkin reality check:
- Cost: The APIM consumption tier starts at about $3 per million requests (with 10M requests included). Unless you’re building the next ChatGPT, you’re probably looking at dollars per month, not hundreds. Compare that to the engineering cost of building and maintaining your own auth infrastructure. You can consult the pricing page for the latest.
- Performance: Yes, you’re adding a network hop. In practice, this is usually 10-50ms of additional latency, which is negligible for most MCP scenarios where you’re doing AI inference anyway. APIM does quite a bit of work to properly cache relevant credentials and data, saving you some more effort on getting it right.
- Reliability: As with all Azure services, APIM has enterprise-grade SLAs and built-in redundancy. Your hand-rolled auth middleware probably doesn’t.
The trade-off is usually worth it unless you’re operating at massive scale. And, if you’re at that scale - you probably have a dedicated platform team handling this stuff anyway.
The user experience that doesn’t suck #
Let’s talk about what really matters as the new spec gains traction: the integrated user experience. Building a protected MCP server is only half the battle, but what about building a great experience for those that want to consume said MCP server?
You know what drives me crazy? Applications that bounce you to seventeen different browser tabs just to log in. It’s 2025, and we’re still treating authentication like it’s the early days of 2005 when we haven’t figured out how to store credentials properly.
When you implement MCP auth the way I mentioned above, and specifically if you are using Microsoft Entra ID inside Visual Studio Code on Windows, something magical happens.
I am not exaggerating - fire up Visual Studio Code, connect to your MCP server that is gated by Entra ID, and watch the modern auth flow unfold. Instead of the usual browser circus, you get a clean, native Web Account Manager (WAM)-based prompt. It’s something I talked about all the way back in May.
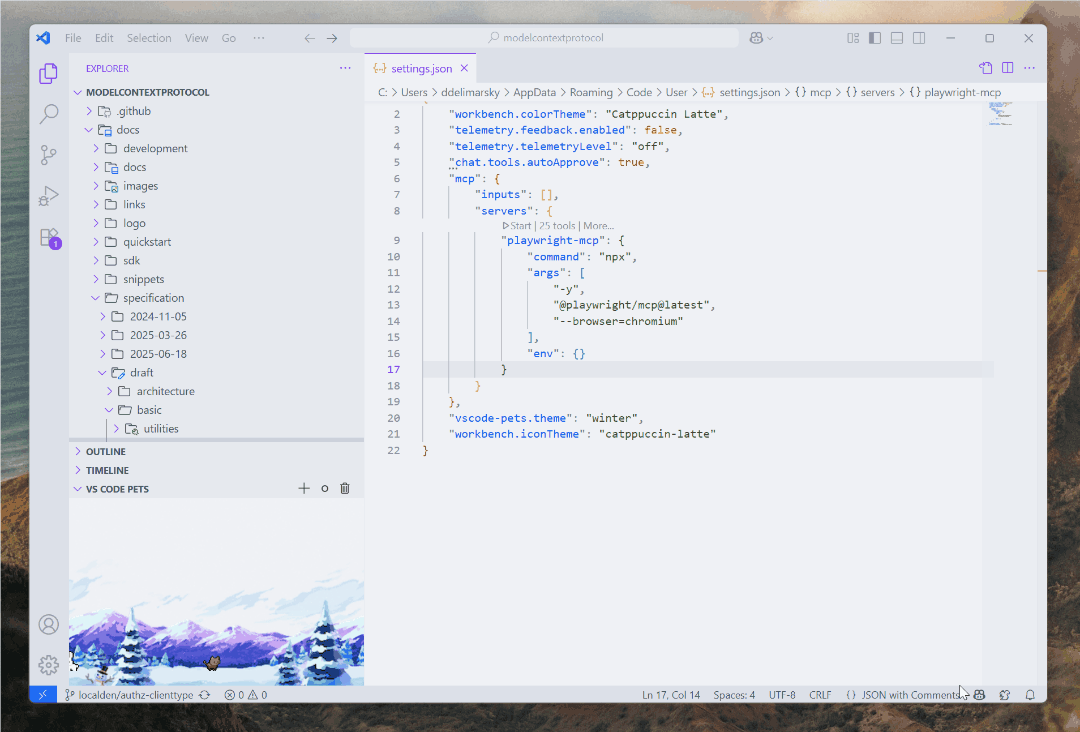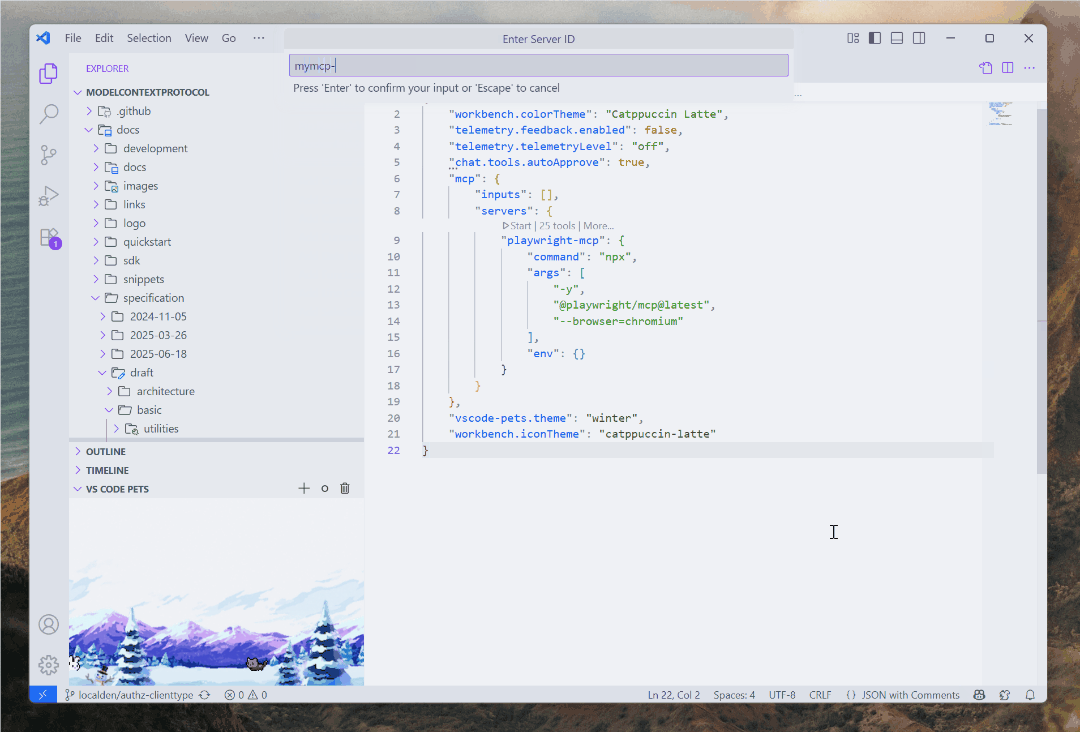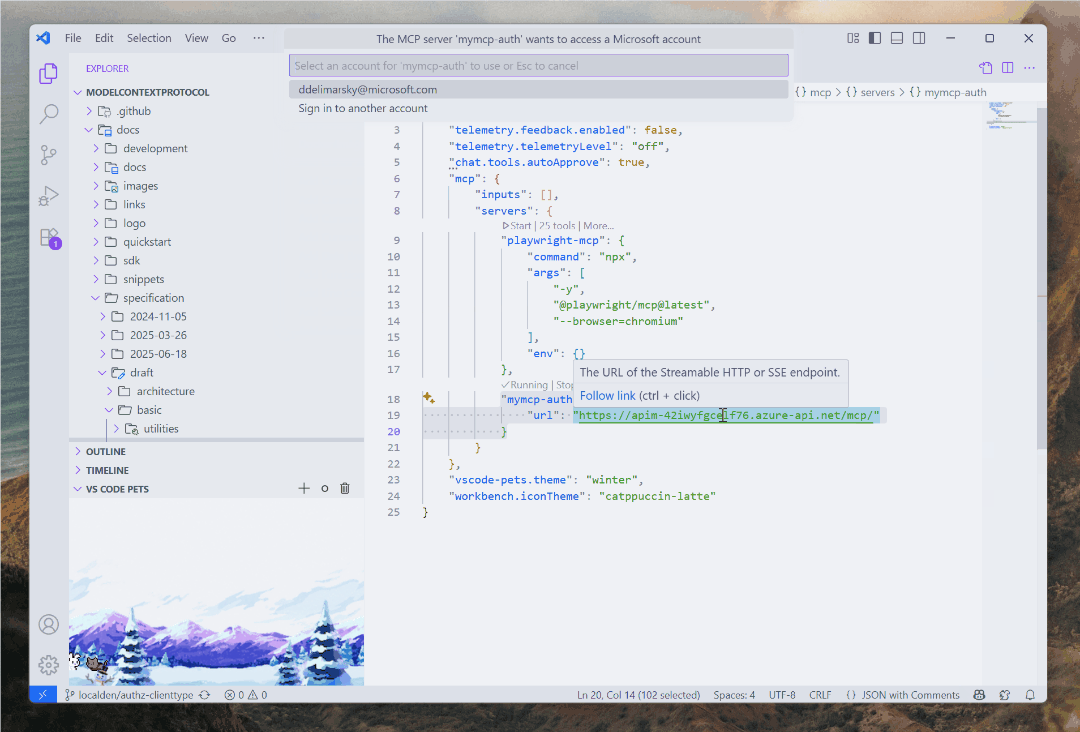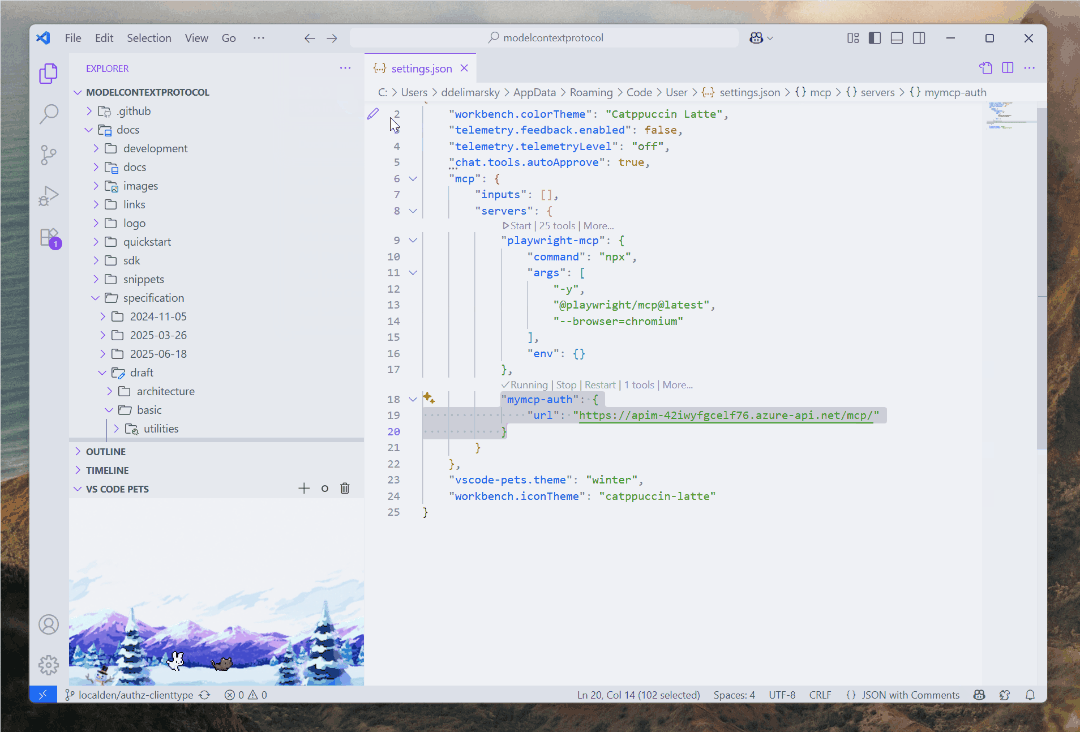
If you’re already logged into Windows with your Microsoft or work account, it’s literally one click. No browser. No typing passwords. No “Please verify you’re not a robot by twisting these seven images to match the rabbit on the right” dance. Even better, if WAM determines that you already met the criteria for auth, you won’t even be prompted to re-auth again. You are already using an account with your OS, why jump through extra hoops? WAM is also handling the local token cache and refresh, which is yet another nice bonus to add to this pile.
This is the kind of user experience that makes me really, really happy. When authentication and authorization is invisible, users (and developers, of course) can focus on what they actually want to build instead of fighting with yet another change in the auth flow logic. That’s a win for everyone.
The elephant in the room: operational complexity #
With all of the above, I focused very heavily on the happy path, but let’s be honest about something. I’ve been telling you about the benefits of using an API gateway for MCP auth, but I’d be doing you a disservice if I didn’t talk about the operational complexity you’re also introducing into your infrastructure.
You’re not just adding a component - you’re adding a distributed system.
When your MCP server was a simple, self-contained service, debugging was straightforward. Request comes in, you set a breakpoint, you step through your code. Now you have requests flowing through APIM policies, token validation happening against Entra ID, caching layers, and potential failure points at every hop.
Debugging distributed auth is generally more painful. When something breaks, you’ll be staring at logs across multiple services trying to figure out if the problem is in your APIM policy configuration, Entra ID tenant settings, token scopes, network connectivity, or your actual MCP server code. The error messages from API gateways are often cryptic at best. You should get comfortable with request tracing. For API Management, you can also use Visual Studio Code to debug policies.
Monitoring becomes more complex. You now need to monitor your API gateway health, authorization server availability, token validation latency, and the relationships between all these components. Your simple “Is my server responding?” health check becomes a multi-service dependency graph.
Local development gets harder. When it comes to running the same code locally, running things behind an API gateway is not as simple as just running your MCP server on the development box. You’re either depending on additional infrastructure (self-hosted gateway), bypassing auth entirely (not great for catching auth-related bugs), or tunneling to cloud services (adding latency and potential connectivity issues to your dev loop).
Configuration drift is a real risk. Your auth logic is now split between APIM policies (which might be managed through XML definitions, Bicep templates, Azure CLI, or the Azure portal) and your application configuration. Keeping these in sync across environments becomes a pretty real operational concern.
So why am I still recommending this approach? Because the alternative is worse for most teams. Building and maintaining your own OAuth implementation means you’re taking on all of this complexity anyway, plus the additional burden of implementing the token handling correctly, managing edge cases, staying up to date with security patches, and becoming an expert in a domain that’s not your core business.
But you should go into this with eyes wide open. The complexity doesn’t disappear - it just moves to a different layer of your stack. For anything deployed at scale, make sure you have the operational maturity to handle distributed systems before you add an API gateway to your critical path.
Stop reinventing the wheel #
Look, I get it. Writing authentication code feels important. It feels like you’re really engineering something because of all the complexity, the twists and turns, the new RFCs, and all the fun that comes with reading seventeen pages about client registration. But you know what’s more important? Shipping software that actually solves real problems.
The MCP specification got this right by embracing existing standards like RFC 9728 for Protected Resource Metadata, RFC 8414 for authorization server metadata, and RFC 7591 for Dynamic Client Registration. The community is building on top of what already works, and that’s a great sign for the maturity of the protocol.
Your job as a developer is to follow their lead. Use the tools that already exist. If you are deploying your MCP servers on Azure, let Azure API Management handle the policy enforcement. Let Microsoft Entra ID handle the identity verification. Let the Azure Developer CLI handle the intricacies of infrastructure deployment from your developer machine.
Here’s your action plan as you try out how protected MCP servers work:
- Clone the samples and run
azd upto see it up and running. Connect the deployed MCP servers to Visual Studio Code and see how the authorization flow works. - Familiarize yourself with the official MCP Authorization Specification to understand what’s going on behind the scenes. As a bonus, check out the Security Best Practices document to understand some of the complexities you have to handle if you roll your own implementation of MCP server auth patterns.
- Review the APIM policies in the samples I linked to. Understand how the PRM document is served and how that transfers control to the client.
- Adapt the pattern for your own use case, identity provider, and cloud platform of choice. I talked about Azure API Management as a demo, but the same approach will work in a more generic scenario too.
If you already have an existing MCP server, the migration to Azure API Management is straightforward - you can copy word-for-word the policies in sample servers and use the Azure Developer CLI to push your code to the cloud. Your existing server code doesn’t need to change.
That’s it. No PhD in cryptography required. No late nights debugging JWT minting logic. Just working, secure, standards-compliant authentication and authorization that your users will actually enjoy using.
Because at the end of the day, the best authentication system is the one developers never have to think about.