Easy Spec Reviews With GitHub & Bots
As a Program Manager, part of my job is to write technical specification documents. Our team recently switched to using our very own system (yes, we use the docs.microsoft.com infrastructure internally too) to write technical specs – content is on GitHub and Markdown-based. As part of that came the question – how do we aggregate comments when people review them?
One solution that came up during a weekend hack session was to use GitHub for review comments as well. But how do we make sure that there is a consistent experience across the board? Well… by auto-creating GitHub issues and embedding links to them in the spec themselves. I thought I would use some of the infrastructure that I’ve already put in place, and re-purpose it to the spec review needs. This resulted in SpecBot.
Generally, it works like any other GitHub bot – with the help of web hooks through an Azure-hosted node.js application. When a new commit happens, we send a push event to the bot. See what happens next:
If the x-github-event is push, then we can use node-github, piped through a bot helper class. Once we get the commit, the only thing we need to check is whether the file was added (at this time, I skipped retroactive addition of review items to existing specs), placed in the target directory and is a Markdown file (specs are only .md).
At this point, we need to start reading the content from the doc, if we indeed detected one:
I am still using the bot helper class to perform the content pull – once the GitHub API returns it, it will be in Base64-encoded format, hence there is a need to transform the data into a readable UTF-8 string.
Something to keep in mind with Markdown files that we use is that we also append YAML metadata, to it. There is a variety of reasons for that, but one of the big ones is organizational – it’s a relatively cheap way to add any information related to the content without affecting the content itself. As an example, all specs have a keywords: spec metadata entry, as well as a title.
View this raw to see how the YAML header is structured.
Now, lucky for us, we have yaml-front-matter to read the header content. Once we identify that it has the spec metadata and a filled title, a new issue is created for the spec:
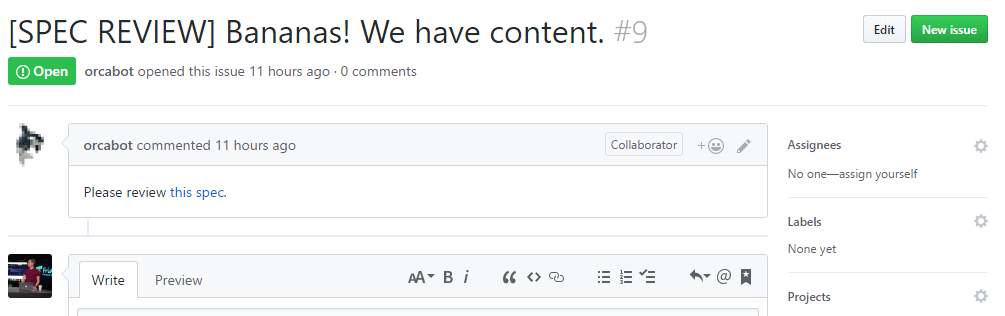
The issue links back to the file, for easy discoverability. The last step is updating the file itself, and that is done by pulling the content, adding an extra line that points to the issue (GitHub API will return the issue URL) at the very end of the file, encoding it back into a Base64 string and committing it into the repo.
Voila, an easy way to organize spec review comments!