Using GitHub Copilot From Inside GitHub Actions
Table of Contents
I enjoy using GitHub Copilot not the least because it really helps me automate the boring and more repetitive tasks fairly easily, and I am big on saving my time not doing boring and repetitive tasks.
A problem bubbled up in my BlogScroll project - people submit their website entries in a structured way, but then I have to go and manually add them to the category list that they picked if the website is approved. A submission may look like this:
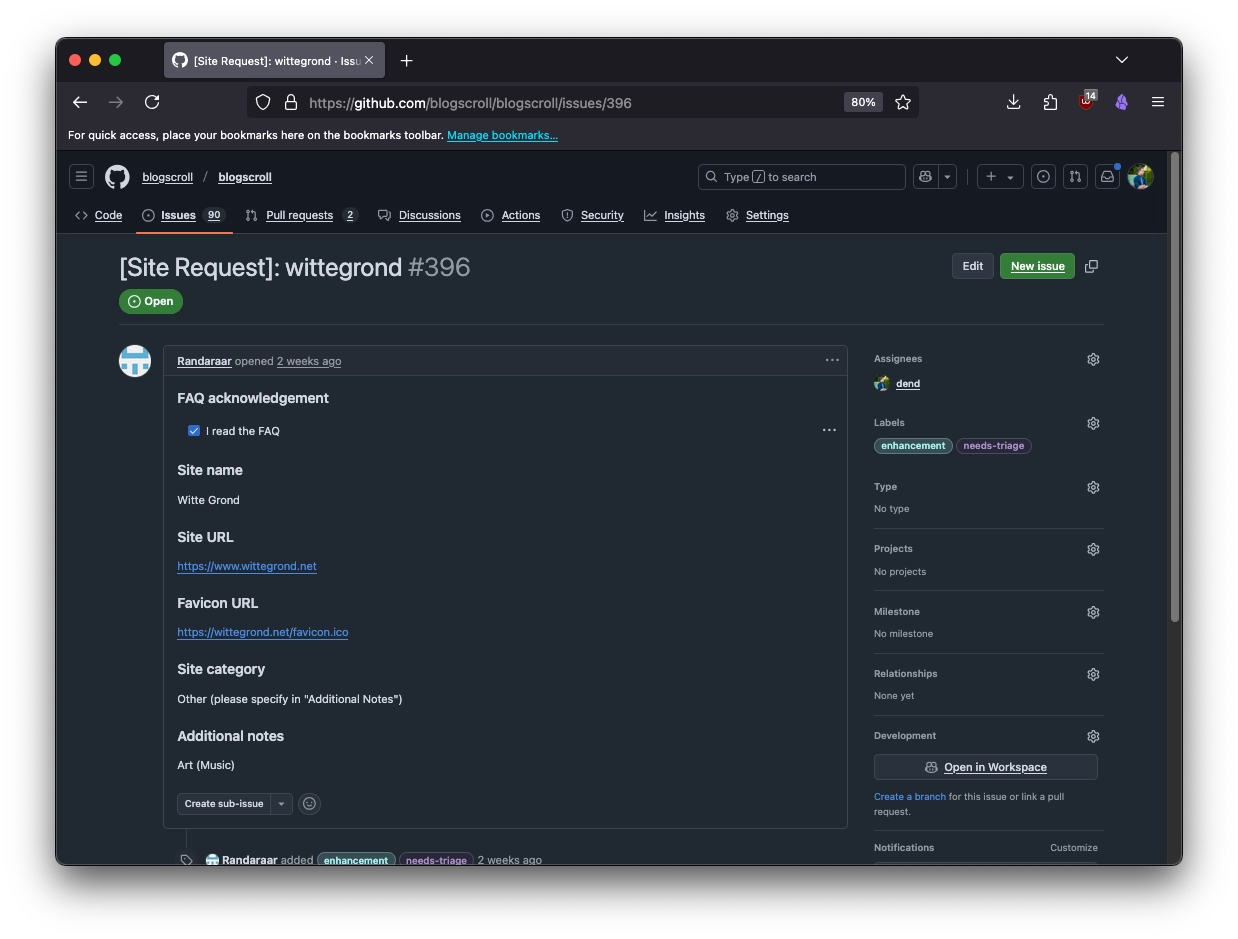
I could tackle this problem in two ways - manually reading the issue, inspecting the page, and then creating a pull request, or go the route of using regular expressions to parse out the body of the issue, and then create a pull request. The latter sounds way more robust, but I thought I’d have some fun and see if I can plug GitHub Copilot to do this for me without me writing custom RegEx.

But why use GitHub Copilot with undocumented APIs when you could probably use any other large language model (LLM) that has an available and documented public API? Azure OpenAI comes to mind as a service to use here!
GitHub Copilot has one amazing differentiator - the ability to carry the context of GitHub items I am dealing with. For example, if I am working within a repository I can very easily provide that repository as context for my prompt, making it possible to structure the output based on the knowledge within that repository. The same benefit is also applicable to issues, and because that’s exactly what I am dealing with for BlogScroll, I thought it’s the best way for me to leverage LLM capabilities without reinventing the wheel and providing extensive information/detailed prompts to another API.
Exploring the fundamentals of the GitHub Copilot API #
One of the interesting things about GitHub Copilot is that it doesn’t yet have a public API, but because I already like to tinker with various APIs, I knew just the tool I needed to inspect the traffic as I was playing around with prompts in the GitHub Copilot web interface - Fiddler. I noticed the following endpoints being used:
- Token endpoint:
https://github.com/github-copilot/chat/token - Thread bootstrap endpoint:
https://api.individual.githubcopilot.com/github/chat/threads - Conversation endpoint:
https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}/messages - Conversation management endpoint:
https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}
At a high level, the endpoints are used like this:
Let’s talk a bit more about the endpoints themselves.
Endpoints #
Token endpoint #
The token endpoint is used to request the GitHub Copilot API token. This is different from your typical GitHub Personal Access Token (PAT) or a standard authentication token, and is specific to the GitHub Copilot flows. To get a token, you need to POST a request with the following headers:
| Header | Value |
|---|---|
Cookie |
Session ID, obtained from a local cookie. You can log in to https://github.com in your browser and then use the Network Inspector to grab the user_session=ABCDE12345 part of the cookie. It’s the only one that is needed to get a token. |
X-Requested-With |
XMLHttpRequest |
GitHub-Verified-Fetch |
true |
Origin |
https://github.com |
And as a reminder, the endpoint is:
https://github.com/github-copilot/chat/token

Hold on - you're using cookies instead of a more robust OAuth approach? Wouldn't this be the worst way to go about solving the problem of minting a new API token?
Yes, this is a bit hacky to rely on a cookie, but remember what I said - none of this is for production use. It’s just a fun experiment. Fun fact - if you use the GitHub CLI (gh), and specifically if you inspect the traffic for the gh copilot set of commands, you will notice that you can get a different kind of token for CLI-based prompts (starting with gho_).
In those scenarios, you can use Device Flow together with the GitHub CLI client ID to get an access token that you can use with GitHub’s Copilot API endpoints, however I have noticed that if you are not using a session-based token (that is - minted from a user_session), then the context for issues and the repository are completely ignored and I am getting answers that are not quite accurate. Maybe I am not looking in the right places, but because this is a “for fun” project, I wasn’t too worried about the durability of my approach.
Either way once you POST to the endpoint above with the correct data in the headers, you should be able to get a JSON response like this:
{
"token": "SUPER_SECRET_VALUE",
"expiration": "2025-01-26T03: 03: 57.000Z"
}
The token itself is short-lived (30 minutes), but the session is not, so as long as you keep a user_session reference and haven’t logged out from the GitHub web interface, you can continue to use it to mint new tokens as you see fit.
Thread bootstrap endpoint #
Once you have a token, you can now bootstrap new threads (that is - new chats) with GitHub Copilot. To successfully create a new thread, you need to POST a request to the following endpoint:
https://api.individual.githubcopilot.com/github/chat/threads
You will also need to make sure that you include the following headers:
| Header | Value |
|---|---|
Authorization |
GitHub-Bearer {api_token} |
Content-Type |
application/json |
The {api_token} value is the token that you received from the token endpoint. If the thread is created, you will get a response like this:
{
"thread_id": "54c1eecf-b8f6-4e14-aabf-1f26c482220d",
"thread": {
"id": "54c1eecf-b8f6-4e14-aabf-1f26c482220d",
"name": "",
"repoID": 0,
"repoOwnerID": 0,
"createdAt": "2025-01-26T02:49:42.92162332Z",
"updatedAt": "2025-01-26T02:49:42.92162332Z",
"sharedAt": null,
"associatedRepoIDs": []
}
}
You will need the thread_id value to start prompting the model.
Conversation endpoint #
The URI for the endpoint is the following:
https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}/messages
The {thread_id} value is the GUID you obtained when you bootstrapped a new thread. You will also need the following headers for each request:
| Header | Value |
|---|---|
Authorization |
GitHub-Bearer {api_token} |
Content-Type |
application/json |
And just like I mentioned before, the {api_token} value is the token that you received from the token endpoint. To submit a prompt, you will need to POST some JSON, and not just any JSON, but a blob formatted like this:
{
"content": "test",
"intent": "conversation",
"references": [
{
"id": 314958631,
"name": "blogscroll",
"ownerLogin": "blogscroll",
"ownerType": "Organization",
"readmePath": "README.md",
"description": "📜 An aggregator of independently-owned blogs",
"commitOID": "a14a4a6e8dfa2e0ddec0f66b01427db562dca971",
"ref": "refs/heads/main",
"refInfo": {
"name": "main",
"type": "branch"
},
"visibility": "public",
"languages": [
{
"name": "Python",
"percent": 48.3
},
{
"name": "HTML",
"percent": 31.1
},
{
"name": "CSS",
"percent": 13.2
},
{
"name": "Shell",
"percent": 7.4
}
],
"customInstructions": null,
"type": "repository"
}
],
"context": [
{
"id": 314958631,
"name": "blogscroll",
"ownerLogin": "blogscroll",
"ownerType": "Organization",
"readmePath": "README.md",
"description": "📜 An aggregator of independently-owned blogs",
"commitOID": "a14a4a6e8dfa2e0ddec0f66b01427db562dca971",
"ref": "refs/heads/main",
"refInfo": {
"name": "main",
"type": "branch"
},
"visibility": "public",
"languages": [
{
"name": "Python",
"percent": 48.3
},
{
"name": "HTML",
"percent": 31.1
},
{
"name": "CSS",
"percent": 13.2
},
{
"name": "Shell",
"percent": 7.4
}
],
"customInstructions": null,
"type": "repository",
"path": ""
}
],
"currentURL": "https://github.com/blogscroll/blogscroll",
"streaming": true,
"confirmations": [],
"customInstructions": [],
"mode": "assistive",
"parentMessageID": "",
"tools": []
}
Now, the JSON can be significantly simpler if you omit the references and context sections - and you can absolutely do that. You’ll see what I do with it below, but it’s important that you keep these in (or modify them for the right context) if you want to prompt the model for specifics around GitHub entities (such as, in the case above, my blogscroll/blogscroll repository).
The content property is the prompt itself. When you submit the request, the data will be returned in the shape of Server-Sent Events (SSE) data. The response will be streamed and it will look like this:
data: {"type":"content","body":""}
data: {"type":"content","body":"The"}
data: {"type":"content","body":" `"}
data: {"type":"content","body":"blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":"/blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":"`"}
data: {"type":"content","body":" repository"}
data: {"type":"content","body":" is"}
data: {"type":"content","body":" an"}
data: {"type":"content","body":" open"}
data: {"type":"content","body":" directory"}
data: {"type":"content","body":" of"}
data: {"type":"content","body":" personal"}
data: {"type":"content","body":" sites"}
data: {"type":"content","body":" and"}
data: {"type":"content","body":" blogs"}
data: {"type":"content","body":","}
data: {"type":"content","body":" maintained"}
data: {"type":"content","body":" entirely"}
data: {"type":"content","body":" on"}
data: {"type":"content","body":" Git"}
data: {"type":"content","body":"Hub"}
data: {"type":"content","body":"."}
data: {"type":"content","body":" It"}
data: {"type":"content","body":" was"}
data: {"type":"content","body":" created"}
data: {"type":"content","body":" by"}
data: {"type":"content","body":" Den"}
data: {"type":"content","body":" Del"}
data: {"type":"content","body":"im"}
data: {"type":"content","body":"ars"}
data: {"type":"content","body":"ky"}
data: {"type":"content","body":" to"}
data: {"type":"content","body":" bring"}
data: {"type":"content","body":" attention"}
data: {"type":"content","body":" to"}
data: {"type":"content","body":" independently"}
data: {"type":"content","body":"-owned"}
data: {"type":"content","body":" blogs"}
data: {"type":"content","body":" and"}
data: {"type":"content","body":" personal"}
data: {"type":"content","body":" websites"}
data: {"type":"content","body":","}
data: {"type":"content","body":" facilitating"}
data: {"type":"content","body":" their"}
data: {"type":"content","body":" discovery"}
data: {"type":"content","body":"."}
data: {"type":"content","body":" For"}
data: {"type":"content","body":" more"}
data: {"type":"content","body":" details"}
data: {"type":"content","body":","}
data: {"type":"content","body":" you"}
data: {"type":"content","body":" can"}
data: {"type":"content","body":" check"}
data: {"type":"content","body":" the"}
data: {"type":"content","body":" ["}
data: {"type":"content","body":"README"}
data: {"type":"content","body":" file"}
data: {"type":"content","body":"]("}
data: {"type":"content","body":"https"}
data: {"type":"content","body":"://"}
data: {"type":"content","body":"github"}
data: {"type":"content","body":".com"}
data: {"type":"content","body":"/blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":"/blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":"/blob"}
data: {"type":"content","body":"/a"}
data: {"type":"content","body":"14"}
data: {"type":"content","body":"a"}
data: {"type":"content","body":"4"}
data: {"type":"content","body":"a"}
data: {"type":"content","body":"6"}
data: {"type":"content","body":"e"}
data: {"type":"content","body":"8"}
data: {"type":"content","body":"dfa"}
data: {"type":"content","body":"2"}
data: {"type":"content","body":"e"}
data: {"type":"content","body":"0"}
data: {"type":"content","body":"d"}
data: {"type":"content","body":"dec"}
data: {"type":"content","body":"0"}
data: {"type":"content","body":"f"}
data: {"type":"content","body":"66"}
data: {"type":"content","body":"b"}
data: {"type":"content","body":"014"}
data: {"type":"content","body":"27"}
data: {"type":"content","body":"db"}
data: {"type":"content","body":"562"}
data: {"type":"content","body":"d"}
data: {"type":"content","body":"ca"}
data: {"type":"content","body":"971"}
data: {"type":"content","body":"/"}
data: {"type":"content","body":"README"}
data: {"type":"content","body":".md"}
data: {"type":"content","body":")"}
data: {"type":"content","body":" and"}
data: {"type":"content","body":" the"}
data: {"type":"content","body":" ["}
data: {"type":"content","body":"repository"}
data: {"type":"content","body":" metadata"}
data: {"type":"content","body":"]("}
data: {"type":"content","body":"https"}
data: {"type":"content","body":"://"}
data: {"type":"content","body":"github"}
data: {"type":"content","body":".com"}
data: {"type":"content","body":"/blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":"/blog"}
data: {"type":"content","body":"scroll"}
data: {"type":"content","body":")."}
data: {"type":"complete","id":"9a0c48a1-e258-41f5-a74f-38584b59e048","parentMessageID":"","turnId":"","createdAt":"2025-01-26T03:02:34.621459216Z","references":[],"role":"assistant","intent":"conversation","copilotAnnotations":{"CodeVulnerability":[],"PublicCodeReference":[]}}
You can parse the data out and concatenate it into one string from all the content pieces, but on that shortly.
Conversation management endpoint #
The last, but not least important endpoint, is the one we can use to cleanup existing conversations (identified by thread_id). The endpoint is:
https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}
You probably already suspect what headers will be needed:
| Header | Value |
|---|---|
Authorization |
GitHub-Bearer {api_token} |
Content-Type |
application/json |
If you send a DELETE request to this endpoint, the conversation will be erased. You will see why this is needed in the following section.
Stitching it all together in a Python script #
Now that you’re familiar with the endpoints, it’s time to get back to the problem I started this post with:
- I have BlogScroll submissions.
- For each submission, I want to be able to extract the data in a TOML format (similar to how I already have it in some files).
- I then use that TOML blob as a new entry for the category-specific file that someone chose for their site.
Oh yes, and for each issue I know that I can provide the context to GitHub Copilot, that will ensure that the AI model looks just at that specific issue and is not hallucinating a response. Let’s take a look at my full script (you can also see it on GitHub) that gets the data out with the help of GitHub Copilot APIs:
import requests
import sseclient
import json
import argparse
def get_args():
"""Parse and return command-line arguments."""
parser = argparse.ArgumentParser(description="Automate BlogScroll entry identification with GitHub Copilot.")
parser.add_argument("--session-id", required=True, help="The session ID to use.")
parser.add_argument("--issue-id", required=True, help="Issue ID (not number) for which context extraction is happening.")
parser.add_argument("--issue-number", required=True, help="Issue number for which context extraction is happening.")
return parser.parse_args()
def fetch_api_token(session_id, token_url):
"""Fetch the API token using the provided session ID."""
headers = {
'Cookie': session_id,
'X-Requested-With': 'XMLHttpRequest',
'GitHub-Verified-Fetch': 'true',
'Origin': 'https://github.com'
}
response = requests.post(token_url, headers=headers)
if response.status_code not in [200, 201]:
raise Exception(f"Failed to fetch API token. Status code: {response.status_code}, Response: {response.text}")
return response.json().get('token')
def bootstrap_thread(api_token, bootstrap_url):
"""Initialize a conversation thread and return the thread state."""
headers = {
"Authorization": f"GitHub-Bearer {api_token}",
"Content-Type": "application/json"
}
response = requests.post(bootstrap_url, headers=headers)
if response.status_code not in [200, 201]:
raise Exception(f"Failed to bootstrap thread. Status code: {response.status_code}, Response: {response.text}")
return response.json()
def build_json_prompt(issue_number, issue_id):
"""Build the JSON prompt for the thread conversation."""
return json.dumps({
"content": (
"Use this file as a general reference for TOML format that I want you to use: web/data/categories/technology/list.toml in the blogscroll/blogscroll repository. DO NOT USE THIS CONTENT IN THE RESPONSE. "
"If your response includes ANY content from this file, it will be considered incorrect. "
"From the current issue body, generate a TOML blob that can be inserted into the file defined as the category property. "
"If the generated TOML does not represent the CURRENT ISSUE BODY, it will be considered incorrect. "
"The result ID (in square brackets) should always be in the form [blog.] where what follows after the period is the site domain part from the Site URL section without the protocol, and the periods are omitted entirely. "
"Just in the TOML header (between square brackets) that represents the site there could be only alphanumeric characters. No hyphens, underscores, or any other special characters. "
"The [blog.] part should be in lowercase and ALWAYS there. The period separating it from the rest should ALWAYS be there. "
"The domain part after 'blog.' should be in lowercase and always there. Make sure to letters are missing, even if they are duplicated. "
"Include the file path where the blob needs to be inserted. The file path is of the pattern web/data/categories/REPLACE-CATEGORY-HERE/list.toml. "
"The REPLACE-CATEGORY-HERE should match 1:1 the category that is provided in the issue body, in the Site category section."
"The TOML content should NOT contain any properties other than name, url, and favicon. If other properties are present, the results will be considered incorrect. "
"Return data in JSON format (just the JSON). JSON response should have two properties - `content` for the TOML content, and `file_path` for the file path."
"UNDER NO CIRCUMSTANCES in the response you produce should you include Markdown markers (```) that delineate the code fragment."
"Just return the raw JSON without the triple ticks. If your response contains ```, it will be considered incorrect."
),
"intent": "conversation",
"context": [
{
"type": "issue",
"id": int(issue_id),
"number": int(issue_number),
"repository": {
"id": 314958631,
"name": "blogscroll",
"owner": "blogscroll"
}
}
],
"currentURL": f"https://github.com/blogscroll/blogscroll/issues/{issue_number}",
"streaming": True,
"confirmations": [],
"customInstructions": [],
"mode": "assistive",
"parentMessageID": "",
"tools": []
})
def fetch_thread_responses(api_token, prompt, conversation_url):
"""Send a conversation prompt and stream responses."""
headers = {
"Authorization": f"GitHub-Bearer {api_token}",
"Content-Type": "application/json"
}
response = requests.post(conversation_url, headers=headers, stream=True, data=prompt)
if response.status_code not in [200, 201]:
raise Exception(f"Failed to send prompt. Status code: {response.status_code}, Response: {response.text}")
client = sseclient.SSEClient(response)
response_content = ''
for event in client.events():
data = json.loads(event.data)
if data.get('type') == 'content':
response_content += data['body']
return response_content
def delete_thread(api_token, conversation_url):
"""Send a conversation prompt and stream responses."""
headers = {
"Authorization": f"GitHub-Bearer {api_token}",
}
response = requests.delete(conversation_url, headers=headers)
if response.status_code not in [200, 201, 204]:
raise Exception(f"Failed to delete thread. Status code: {response.status_code}, Response: {response.text}")
return True
def main():
args = get_args()
session_id = args.session_id
issue_id = args.issue_id
issue_number = args.issue_number
token_endpoint = "https://github.com/github-copilot/chat/token"
thread_bootstrap_endpoint = "https://api.individual.githubcopilot.com/github/chat/threads"
api_token = fetch_api_token(session_id, token_endpoint)
thread_state = bootstrap_thread(api_token, thread_bootstrap_endpoint)
thread_id = thread_state['thread_id']
json_prompt = build_json_prompt(issue_id=issue_id, issue_number=issue_number)
thread_conversation_endpoint = f"https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}/messages"
response_content = fetch_thread_responses(api_token, json_prompt, thread_conversation_endpoint)
print(response_content)
thread_conversation_endpoint = f"https://api.individual.githubcopilot.com/github/chat/threads/{thread_id}"
thread_deleted = delete_thread(api_token, thread_conversation_endpoint)
if __name__ == "__main__":
main()
This seems like a lot, but it’s a lot less scary if I tell you that the bulk of it is just wrapping the endpoints I mentioned above:
get_argsis responsible for getting command line arguments from the terminal. We need three of them:--session-id- the value of the session cookie.--issue-id- unique issue ID (not the number - the ID) for the new BlogScroll website submission.--issue-number- unique issue number (this is what you see in the GitHub UI).
fetch_api_tokenis responsible for minting a new API token based on the session details.bootstrap_threadcreates a new thread.build_json_promptconstructs the JSON structure for the prompt we’re submitting to GitHub Copilot. This includes detailed instructions on how to read the data from the issue body and then structure the response.fetch_thread_responseswill stream the response from the GitHub Copilot API when provided a prompt. I use thesseclient-pylibrary to get the SSE response and combine the pieces in one final string.delete_threadwill cleanup the thread from the history, because we don’t need ephemeral threads to pollute the web UI.
You might also notice that there are a few values in my prompt that are hardcoded and others that are dynamic. Repository metadata is hardcoded, because I only plan to run this script within one repository - blogscroll/blogscroll. The issue data, in turn, is dynamic, and is inserted from the command line arguments provided when the script is executed. You will see soon how that’s used from within GitHub Actions.
I also alluded to the fact that I wanted to clean up the conversation after execution. If that’s not done, you end up with, well, this:
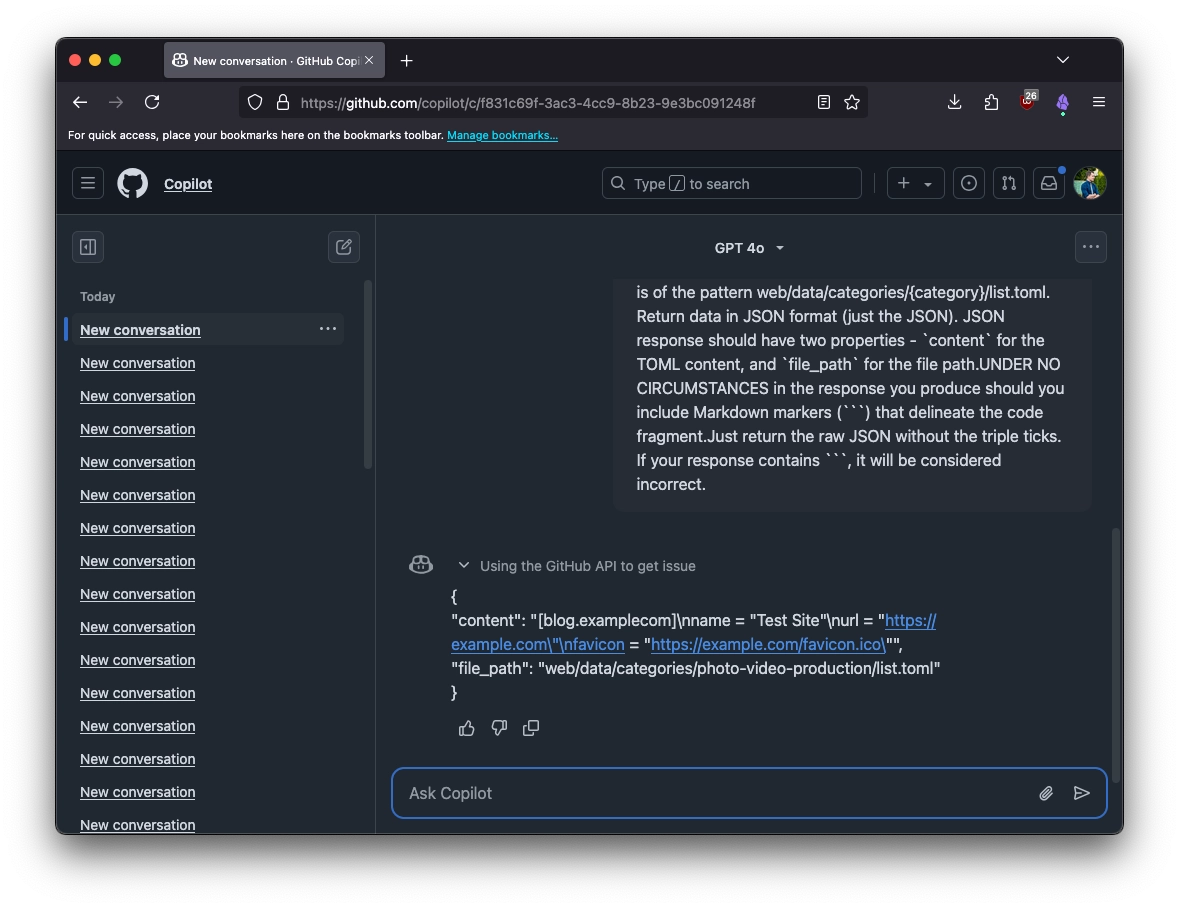
Not ideal - I don’t want to manually delete them later, so it’s much easier to do it in the script.
When the script runs, the TOML data, along with the path to the file that is inferred from the category that the user provided is returned in one JSON blob:
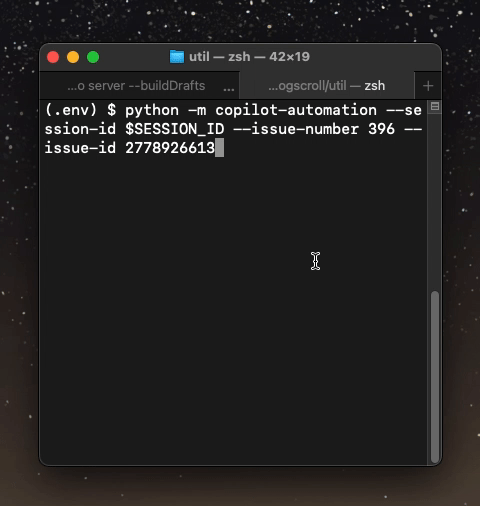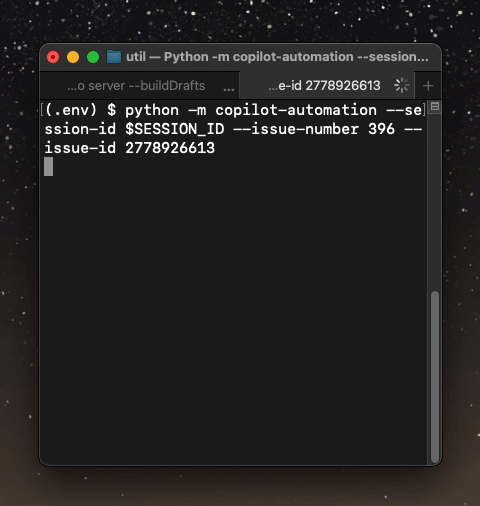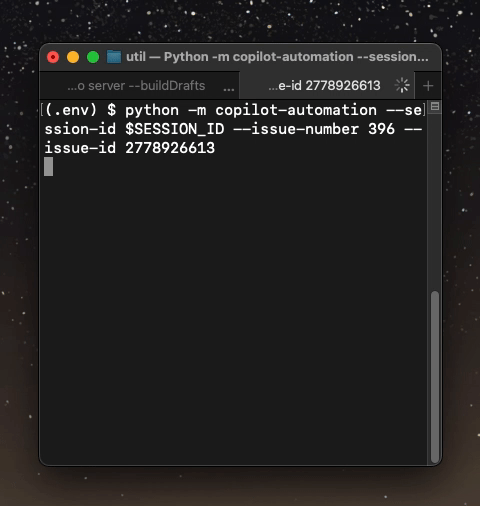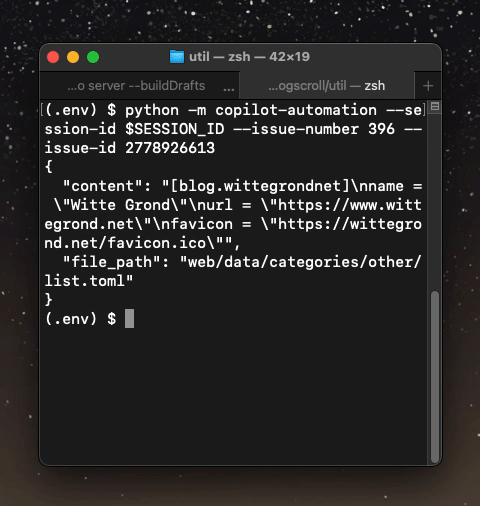
Here, you can see that based on the issue metadata, GitHub Copilot successfully provided a valid JSON blob that contains all the data that I need to insert it into an existing blog scroll list file.
Using the script from GitHub Actions #
Next, I needed to make sure that I am actually capable of invoking the script from a GitHub Action. I decided that the trigger for that should be me submitting an /approved comment to an issue. In turn, that action should:
- Label the issue as
approvedand remove theneeds-triagelabel. - Run the
copilot-automationscript from above and get the JSON blob. - Based on the JSON blob, determine the file that needs to be updated, and add the TOML blob to it.
- Commit the change to an
automation-updatebranch and push it to my repo. - Create a pull request, if one doesn’t already exists.
This way, I can significantly reduce the time I spend manually handling submissions. The action (also - source on GitHub) looks like this:
name: Approve Issue
on:
issue_comment:
types: [created]
jobs:
approve:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Check comment author and content
id: check_comment
uses: actions/github-script@v6
with:
script: |
if (context.payload.comment.user.login === 'dend' && context.payload.comment.body.trim() === '/approved') {
core.setOutput('approved', 'true');
} else {
core.setOutput('approved', 'false');
}
- name: Remove 'needs-triage' label and add 'approved'
if: steps.check_comment.outputs.approved == 'true'
uses: actions/github-script@v6
with:
script: |
const issueLabels = await github.rest.issues.listLabelsOnIssue({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number
});
const labels = issueLabels.data.map(label => label.name);
if (labels.includes('needs-triage')) {
await github.rest.issues.removeLabel({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
name: 'needs-triage'
});
}
if (!labels.includes('approved')) {
await github.rest.issues.addLabels({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
labels: ['approved']
});
}
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: Set up Python
if: steps.check_comment.outputs.approved == 'true'
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
if: steps.check_comment.outputs.approved == 'true'
working-directory: util
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Check issue number
if: steps.check_comment.outputs.approved == 'true'
run: |
echo "Issue number: ${{ github.event.issue.number }}"
- name: Get issue ID
id: get_issue_id
if: steps.check_comment.outputs.approved == 'true'
uses: actions/github-script@v6
with:
script: |
const issue = await github.rest.issues.get({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number
});
core.setOutput('issue_id', issue.data.id);
- name: Echo issue ID
if: steps.check_comment.outputs.approved == 'true'
run: |
echo "Issue ID: ${{ steps.get_issue_id.outputs.issue_id }}"
- name: Run copilot-automation script
id: run_copilot_automation
if: steps.check_comment.outputs.approved == 'true'
run: |
set -e # Exit on error
output=$(python -m copilot-automation \
--session-id "${{ secrets.SESSION_ID }}" \
--issue-number "${{ github.event.issue.number }}" \
--issue-id "${{ steps.get_issue_id.outputs.issue_id }}")
echo "Raw output:"
echo "$output"
# Escape the JSON output for GITHUB_OUTPUT
escaped_output=$(echo "$output" | jq -c .)
echo "issue_json=$escaped_output" >> $GITHUB_OUTPUT
working-directory: util
- name: Create and switch to new branch
if: steps.check_comment.outputs.approved == 'true'
run: |
git fetch origin
if git show-ref --quiet refs/remotes/origin/automation-update; then
git checkout automation-update
git pull origin automation-update
else
git checkout -b automation-update
fi
- name: Check for TOML content and update file
if: steps.check_comment.outputs.approved == 'true'
run: |
issue_json='${{ steps.run_copilot_automation.outputs.issue_json }}'
issue_number='${{ github.event.issue.number }}'
./util/update_toml.sh "$issue_json" "$issue_number"
- name: Commit changes
if: steps.check_comment.outputs.approved == 'true'
run: |
issue_number=${{ github.event.issue.number }}
git config --global user.name "github-actions[bot]"
git config --global user.email "github-actions[bot]@users.noreply.github.com"
git add .
git commit -m "Fixes #${issue_number}"
- name: Push changes
if: steps.check_comment.outputs.approved == 'true'
run: |
git push --set-upstream origin automation-update
- name: Check for existing pull request
if: steps.check_comment.outputs.approved == 'true'
id: check_pr
uses: actions/github-script@v6
with:
script: |
const prs = await github.rest.pulls.list({
owner: context.repo.owner,
repo: context.repo.repo,
head: `${context.repo.owner}:automation-update`,
base: 'main',
state: 'open'
});
if (prs.data.length > 0) {
core.setOutput('pr_exists', 'true');
core.setOutput('pr_id', prs.data[0].number);
} else {
core.setOutput('pr_exists', 'false');
}
- name: Create pull request
if: steps.check_comment.outputs.approved == 'true' && steps.check_pr.outputs.pr_exists == 'false'
id: create_pr
uses: actions/github-script@v6
with:
script: |
const pr = await github.rest.pulls.create({
owner: context.repo.owner,
repo: context.repo.repo,
title: `Automatic fixes based on approvals`,
head: 'automation-update',
base: 'main',
body: 'This PR adds websites that were approved in the BlogScroll issue tracker.'
});
const fs = require('fs');
fs.appendFileSync(process.env.GITHUB_OUTPUT, `pr_id=${pr.data.number}\n`);
- name: Post comment on issue
if: steps.check_comment.outputs.approved == 'true'
uses: actions/github-script@v6
with:
script: |
const commit = await github.rest.repos.listCommits({
owner: context.repo.owner,
repo: context.repo.repo,
sha: 'automation-update',
per_page: 1
});
const commit_id = commit.data[0].sha;
const pr_id = '${{ steps.check_pr.outputs.pr_exists }}' === 'true' ? '${{ steps.check_pr.outputs.pr_id }}' : '${{ steps.create_pr.outputs.pr_id }}';
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: `Commit was created to fix #${context.issue.number}: ${commit_id}. You can track the change propagation in #${pr_id}`
});
Once again - a scary bunch of YAML, but at its core it’s not super complicated. Let’s walk through it.
- Check out the repository.
- Check comment author and content - this step ensures that the comment is
/approvedand the author is me (dend). If that is the case, setapprovedtotrue. Otherwise, set it tofalse. This will be used in all subsequent steps. - Remove
needs-triagelabel and addapproved- checks to make sure that the labels are not already applied, and adjusts as needed. - Set up Python- installs Python 3 on the runner.
- Install dependencies - installs the packages in
requirements.txtthat are needed for mycopilot-automationPython script. - Check issue number - prints the issue number. Used for debugging purposes, mostly.
- Get issue ID - gets the underlying issue ID (not the number) that I will need for my
copilot-automationscript. - Echo issue ID - prints the issue ID. Also used for debugging purposes.
- Run copilot-automation script - run the Python script and get the JSON blob representing the data from the issue.
- Create and switch to new branch - make sure that we’re operating on a new or existing
automation-updatebranch. - Check for TOML content and update file - uses a shell script I put together that updates the TOML file with new content or amends it if the issue was already covered before. This is done with the help of TOML comments that clearly identify which site is coming from which issue.
- Commit changes - commits the changes with the help of
git. - Push changes - pushes the changes to the repository.
- Check for existing pull request - checks if a pull request from
automation-updatetomainalready exists. - Create pull request - creates a new pull request if one doesn’t exist.
- Post comment on issue - posts a comment within the issue that tells the submitter where they can find their new site entry.
And as an additional piece of configuration, I created a SESSION_ID secret in my repository that is used with the Python script inside GitHub Actions. This way I won’t have to hardcode it in the script itself and risk exposure.
Whew, that was a lot. But, let’s see this in action.
Not bad! I now saved myself countless hours of doing manual things, as well as a few hours of writing of regular expressions - all because GitHub Copilot can successfully use the context of the issue I am working on and providing output in the exact format I am requesting.
Conclusion #
While I, of course, can and will never recommend using undocumented APIs in any production workloads, this was a fun experiment and I am happy that GitHub Copilot actually provides the expected output in all of the test cases I had. It took some prompt fine-tuning, but ultimately I landed on one (you can see it in my script above) that gets the job done consistently.
If you would like to try GitHub Copilot, you can get it for free (2,000 completions per month, 50 chat messages per month). When ready, you can easily upgrade to GitHub Copilot Pro.