How We Build Documentation For .NET-Based SDKs
Table of Contents
If you are following the news around our new technical documentation experience, you probably know that last week we revamped our managed reference experience and launched the .NET API Browser. In today’s post, I thought I would go into the nitty-gritty of the process and talk about how exactly we generate reference documentation for .NET Framework and related managed SDKs.
As a starting point, it’s worth clearly defining what we see as “managed reference”. This is an umbrella term that describes all API documentation that relates to SDKs or toolkits built on top of the .NET platform. In abstract terms, we document official SDKs that ship ECMA 335 assemblies (aka managed DLLs).
Typically, we would use vanilla DocFX as the primary ingestion & publishing engine – simply connect a GitHub repository, pull the source, and voila – you have yourself the documentation you can work with. At our scale, however, we’ve encountered several roadblocks, specifically around the following areas:
- Versioning – it’s much easier to maintain a clear separation of versions when you have a set of binaries vs. source code commits.
- Multi-framework support – Microsoft ships .NET Framework, .NET Core, .NET Standard, Xamarin, etc. – there is a lot of overlap in terms of content that needs to be documented, and writing de-duping automation post-build.
- Reliability – source is always in flow, and as changes happen and are rolled back, the same will apply to documentation. Especially for pre-release software, you don’t want an accidental commit to result in a doc that goes out to the public. Constraining to a set of ready-to-go binaries means only “approved” SDKs get documented.
Let’s now talk architecture. We chose to standardize on the ECMA XML format, the result of the fantastic work on the Xamarin team. Not only this format gives us enough flexibility in terms of documenting pretty much everything there is to document inside managed DLLs, but its tooling was specifically designed to support the 3 core scenarios that I mentioned above. At the core of the process stays mdoc, a tool that can generate ECMA XML from a set of assemblies that we pass to it.
More than that, Joel Martinez worked hard to add multi-framework support, so that we don’t treat separate sets of DLLs as their own little world, but rather a part of the same common core. But I digress. Here is how we roll:
Step 1: Get all the necessary assemblies #
We work with individual teams to get access to the final compiled assemblies that they release to the public. An ingestion service effectively accesses different shares and NuGet packages to copy the DLLs in a centralized location that our team manages. Yes, I said NuGet too – there is this tool that allows extraction of assemblies from a set of NuGet packages and puts them in the right places.
Within the centralized location, we organize individual SDKs and their versions by “monikers” – a short name that describes a shippable unit. For example, the moniker for .NET Framework 4.7 is netframework-4.7. This is the same short name that you see in the ?view= parameter on .
The ingestion agent does a hash-compare to see if there are changes to binaries before checking them into their final destination.
Step 2: Trigger a documentation pass #
Now that we have all the DLLs in place, the build agent picks up the baton as it’s now time to generate ECMA XML. Because we organized DLLs by monikers, we can use the mdoc frameworks mode to bulk-reflect assemblies. In frameworks mode, mdoc aggregates namespace, type and member information in independent FrameworksIndex/{moniker}.xml files that enumerate everything that is available within a certain “moniker” or “framework” – remember when I mentioned that monikers are shippable units?
The contents of the aforementioned {moniker}.xml file might look something like this:
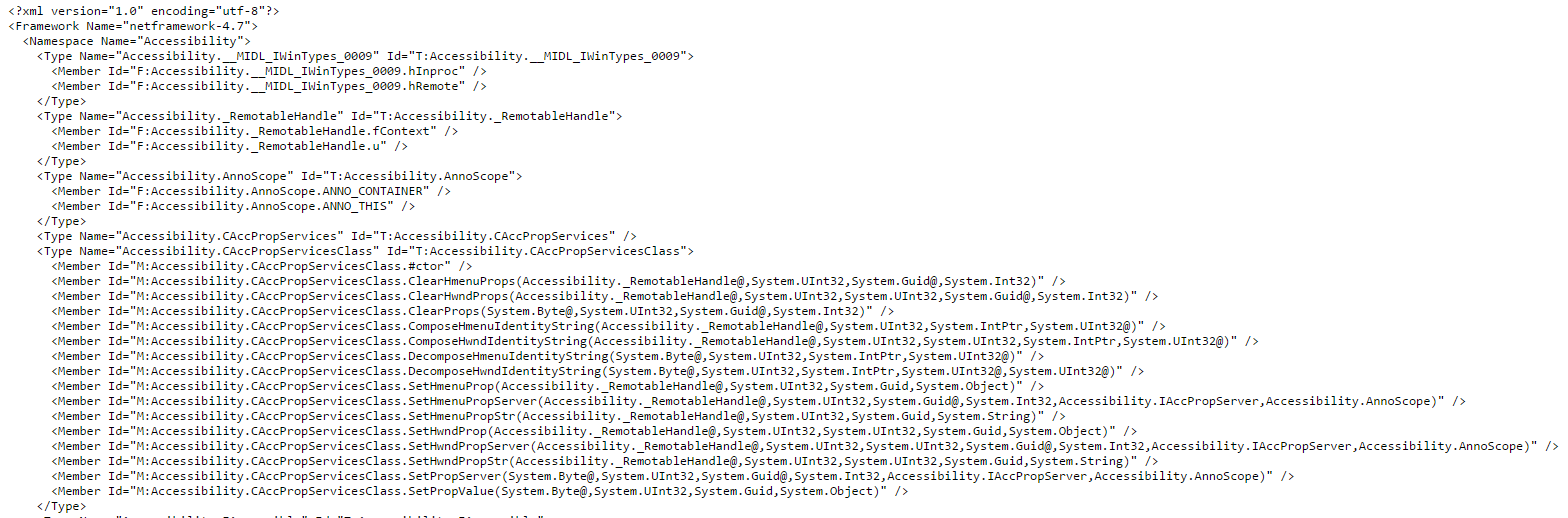
The rest of the XML files are pretty boring – they contain all type information, parameters, information on purpose of APIs – your typical documentation stuff. What’s interesting is that none of those files contain any framework metadata, so if, for example, you are documenting the System namespace, it will be one System.xml that will contain everything for all .NET Framework, .NET Core, .NET Standard and Xamarin. It’s the {moniker}.xml that will determine what from that namespace actually belongs to the framework.
In some special cases, developers also ship documentation files – those XML files that the Roslyn/mono compilers output based on triple-slash comments inside your code (because remember – the comments are not preserved in binaries). Depending on the team, some developers want to not lose the /// documentation, and since we can’t get it from binaries, we have a special build step in place that uses the same mdoc tooling to convert doc XML to ECMA XML, and then perform another pass in frameworks mode and do the diff check to make sure no type information was lost.
Step 3: Check in the XML files #
Once the files are generated, we check them into the content repository. If you are a frequent visitor of the dotnet/docs repo, you might’ve noticed the addition of an xml folder. That’s where the build artifacts are actually published.
Our technical writers and community contributors can go into the repo where the XML files are checked in and add any additional content they want, such as remarks, examples, schemes, diagrams, etc.
Step 4: Prepare & publish #
What many of you might not know is that regardless of what format the files come into the publishing pipeline, they always come out as YAML. As you can imagine, we support documenting many things, like Azure CLI, .NET in form of Markdown articles, [Java SDK documentation][https://learn.microsoft.com/java/api/com.azure.ai.contentsafety?view=azure-java-stable], etc. We can’t just shoehorn everything into ECMA XML, as it was not designed for anything beyond .NET.
On the other hand, the publishing pipeline needs to understand standard markup across the board, hence – YAML for everything. There is a number of processors in place that convert all inputs to a YAML output.
The same happens for ECMA XML – a YAML processor generates the necessary YAML and checks that output in its final, publishing, destination, along with many other .NET reference pieces. From there on, it gets converted to HTML, hosted and rendered on docs.microsoft.com.
Here is a fun fact for you – we actually do support Markdown inside ECMA XML! Yes, you can do that via a custom format element:
![CDATA[
## Your Markdown Here
]
This is only allowed inside certain regions of the XML file (more details in the next installment) but our processor will interpret that in a different way than the rest of the XML. So if you, the end-user, are not familiar with the XML format, you can still leverage Markdown inside ECMA XML with no functionality loss.
What’s next? #
Even more automation. There are quite a few steps in the process that require manual intervention, and our main goal here is to automate even the smaller details.