Hidden Xbox APIs: Backing Up Media Captures
Table of Contents
Recently my Xbox started yelling at me every time I started taking a new game capture, reminding me that the storage for my account is full on the Xbox Live network. When I first got it, I thought that it had something to do with the fact that I am blocking outbound telemetry requests through PiHole, and all of a sudden, my local cache filled up. I’ve had that issue before when blanket-banning domains, which resulted in my account not getting any achievements because some domains were shared between telemetry and feature services.
This seemed to be different.
It seemed that six years into taking screenshots and 30 second video clips, Xbox Live finally said “enough” and cut me off from storing more. Here’s the thing though - I didn’t want to lose all those game captures, since they captured some (not all) of the fun moments I had gaming on the console. That included goofy moments in Rocket League, clutch wins in Halo 5, to catching baffling bugs in Grand Theft Auto: San Andreas Definitive Edition. Now, unlike a lot of storage providers, Xbox Live does not have a storage account akin to Google Drive or Dropbox where I can just log in and download all the content I’ve ever stored on the network. Instead, I have to use the app to do it - one by one. There is, for some puzzling reason, also zero web-facing features for this on the Xbox website.
Now, if I wanted to download all my screenshots I could of course rely on the app, and go one-by-one for however many hundreds of captures I had. That would be one way to do it, that would probably take me weeks. Unfortunately, I couldn’t find a “Download All” button either. And in typical fashion, I decided that I’ll write a solution to this problem myself by using the good ol’ man-in-the-middle (MITM) toolbox.
When I activated the notification on my Xbox by holding the Xbox button, I could clearly see all the screenshots and videos that I’ve ever taken through my Xbox consoles.
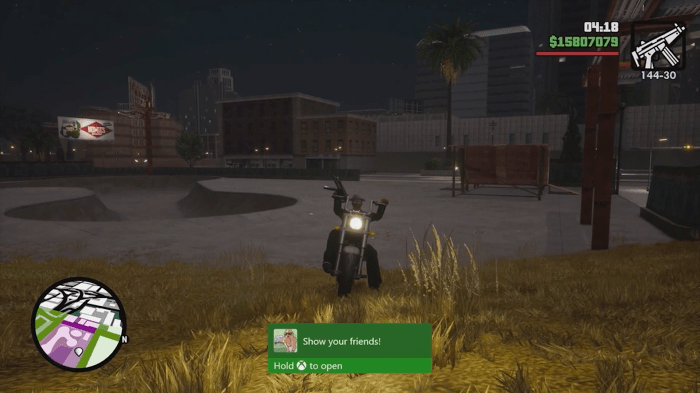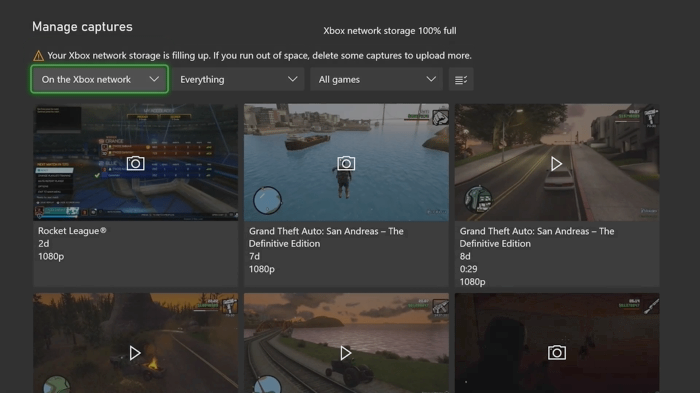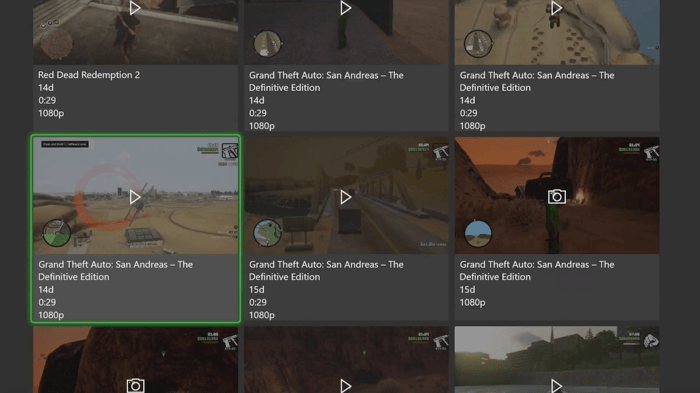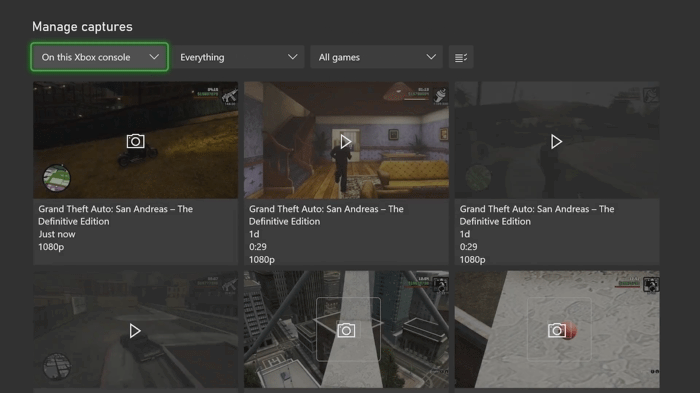
They were there, and there had to be an API behind the scenes that would return all those. Here’s the problem, though - I had a hunch that dealing with certificates on an Xbox would be a pain (for good reason). So instead, why not use something like an iOS device with an Xbox app installed, that can obtain all the screenshots for me? The Xbox for iPad app was a great test space for this experiment!
I’ll skip the boring stuff that I’ve explained several times in other blog posts - I used mitmproxy on my development machine, with a provisioned MITM certificate on my own iPad. You can read more about this setup in an article from way back in the day.
As I fired up the Xbox app, mitmproxy came to life with a lot of requests to the Xbox Live services for a lot of different data. For this particular exercise, I didn’t care much about the user-related auth requests or game metadata - I wanted my captures, and my captures I will get. two requests caught my attention, going to these two endpoints:
https://mediahub.xboxlive.com/gameclips/searchhttps://mediahub.xboxlive.com/screenshots/search
Bingo - I think I got ’em. Looking at the request details, there are several peculiar details:
- The requests use an authorization token in the form of
XBL3.0 x=A_VERY_LONG_STRING_HEREthat is attached to theAuthorizationheader. This seems to be somewhat covered in the official docs, but with very sparse details. There is a user hash and a token, which I probably should explore in a different blog post. - Calls to these endpoints are
POSTrequests with JSON payloads in the body, determining what needs to be searched. - The calls return JSON metadata along with URLs for every clip and screenshot that the user has ever taken, with pagination support. That helps sequence the requests and not return way too much information at once.
- JSON payloads also contain OData-like queries that enable setting constraints to the data that is being downloaded.
All of this seems like a great starting point for me backing up my captures. Now it’s time to automate the process and make sure that I am able to store the content locally. To do that, I put together a Python application that, by the way, is available on GitHub. Here is what the code looks like in practice to download the content (both screenshots and videos) along with thumbnails and metadata (because why not) locally:
def DownloadData(endpoint, xuid, download_location, token, continuation_token = None):
print(f'Downloading from the {endpoint} endpoint...')
content_entities = GetContentEntities(xuid, endpoint, token, continuation_token)
# We just want the local IDs for now to make sure that we know what needs to be
# downloaded. The URLs here are not used for downloads.
local_ids = [e.localId for e in content_entities.values]
print(f'Obtained {len(local_ids)} content IDs.')
if not local_ids == None:
for local_id in local_ids:
print(f'Currently downloading content with ID: {local_id}')
entity = GetContentEntity(endpoint, xuid, local_id, token).values[0]
if entity:
metadata_path = os.path.join(download_location, entity.contentId + ".json")
with open(metadata_path, 'w') as metadata_file:
metadata_file.write(MakeJSON(entity))
print(f'Metadata acquisition successful.')
locator = next((x for x in entity.contentLocators if x.locatorType.casefold() == 'download'))
locator_ts = next((x for x in entity.contentLocators if x.locatorType.casefold() == 'thumbnail_small'))
locator_tl = next((x for x in entity.contentLocators if x.locatorType.casefold() == 'thumbnail_large'))
if locator:
print(f'Attempting to download content at {locator.uri}...')
media_path = os.path.join(download_location, os.path.basename(urlparse(locator.uri).path))
try:
urlretrieve(locator.uri, media_path)
except:
print(f'Could not download content at {locator.uri}.')
if locator_ts:
print(f'Attempting to download small thumbnail at {locator_ts.uri}...')
media_path = os.path.join(download_location, 'small_' + os.path.basename(urlparse(locator_ts.uri).path))
try:
urlretrieve(locator_ts.uri, media_path)
except:
print(f'Could not download small thumbnail at {locator_ts.uri}.')
if locator_tl:
print(f'Attempting to download large thumbnail at {locator_tl.uri}...')
media_path = os.path.join(download_location, 'large_' + os.path.basename(urlparse(locator_tl.uri).path))
try:
urlretrieve(locator_tl.uri, media_path)
except:
print(f'Could not download large thumbnail at {locator_tl.uri}.')
else:
print (f'Could not download entity: {local_id}')
try:
DownloadData(endpoint, xuid, download_location, token, content_entities.continuationToken)
except AttributeError:
print('No more continuation tokens. Assuming media of requested class is downloaded completely.')
else:
print('No content entities to process.')
There is quite a bit to unpack here, so I’ll try to do a rough walk-through of the code.
The function accepts several parameters that help craft the queries for content. Those are endpoint (determining whether we need to get screenshots or video clips), xuid (the unique Xbox Live user identifier - this is not the gamer tag), download_location (path on the local machine where the content needs to be exported), token (the XBL 3.0 token captured earlier), and continuation_token (used for pagination to go through the list of results).
With the information at hand, a call to GetContentEntities is done to get the initial list of content entities (screenshots or videos).
GetContentEntities is nothing other than a wrapper around the Python-specific HTTP request code:
def GetContentEntities(xuid, endpoint, token, continuation_token):
request_string = ''
if not continuation_token:
request_string = f'{{"max":500,"query":"OwnerXuid eq {xuid}","skip":0}}'
else:
request_string = f'{{"max":500,"query":"OwnerXuid eq {xuid}","skip":0, "continuationToken": "{continuation_token}"}}'
screenshot_request = request.Request(f'https://mediahub.xboxlive.com/{endpoint}/search', data = request_string.encode("utf-8"), headers = {'Authorization': token, 'Content-Type': 'application/json'})
response = request.urlopen(screenshot_request)
content_entities = None
if response.getcode() == 200:
print ('Successfully got content collection.')
content_entities = json.loads(response.read(), object_hook=lambda d: SimpleNamespace(**d))
else:
print('Could not get a successful response from the Xbox Live service.')
return content_entities
Within this function, I am constructing the OData-like query I mentioned earlier in JSON format, and then passing it to the screenshot or the video clip endpoint. The payload can take two forms. If I am only interested in the first page, I will send something like this:
{
"max": 500,
"query": "OwnerXuid eq 00000000",
"skip": 0
}
On the other hand, if this is not the first page that I am requesting, I can pass a continuationToken field within the JSON (not the query string) that tells the Xbox Live service the page it needs to refer to, as such:
{
"max": 500,
"query": "OwnerXuid eq 00000000",
"skip": 0,
"continuationToken": "SOME_TOKEN_HERE"
}
The continuationToken is available in the initial response if and only if there are pages that follow the results returned the first time. So, if you don’t see one, that just means that there are no more media entities to return.
When the request is complete, I don’t want to be sitting around parsing JSON so I am just transforming it into a neat little object with object_hook and SimpleNamespace.
Up until this point, I’ve only been talking to the Xbox Live services to get the initial data. What happens next? Well, next I am parsing the data and iterating through every entity before calling GetContentEntity to get its metadata and download the actual media. Wait, hold up - didn’t I just download the metadata once? Why do I need to download the same content for each entity once again?
I’ll start by saying that I have zero inside knowledge about the Xbox Live APIs, so maybe my approach is suboptimal. That being said, when I make the first call to Xbox Live to get the list of screenshots and game clips, I indeed get all the relevant metadata to download them. The problem lies in the fact that each download URL for listed private media has a temporary signature, which means that I can only use that link within a limited time window. The link is formatted like this:
https://gameclipscontent-d2009.xboxlive.com/
xuid-YOUR_XUID-private/
content_id.MP4?sv=2015-12-11&sr=b&si=DefaultAccess&sig=SIGNATURE&__gda__=GDA_VALUE
What can happen sometimes is that as I stored the metadata contents in memory and then would go and download them one-by-one, if the Internet is slow or the CDN node assigned to me was bad, by the time I get to the end of the list, the signature would expire and I could no longer download the content. Which means that I have the option - either re-request the full list, and then resume from where I started, or go entity by entity. I chose the latter.
A reader of this blog informed me that I could, as a matter of fact, make my code a bit easier by using maxPageSize as the JSON parameter instead of max. Looks like the Xbox iOS apps have a bug in them and are using an incorrect parameter, since max does nothing and is completely ignored, no matter what value you specify.
GetContentEntity is very similar to GetContentEntities, and in the future I might even wrap that into one function, but what it does is add an extra parameter to the OData query - see if you can spot it:
{
"max": 500,
"query": "OwnerXuid eq 00000000 and localId eq '00000'",
"skip": 0
}
As it turns out, if I just use localId as filter, I can easily get the entity for just one screenshot or game clip - with a refreshed signature (while still using the XBL 3.0 token issued earlier). Not too bad for a start! Once the call is executed, the resulted entity takes the shape of:
{
"contentId": "SOME_CONTENT_GUID",
"contentLocators": [
{
"expiration": "2021-12-09T16:26:27.7909571Z",
"fileSize": 54558069,
"locatorType": "Download",
"uri": "https://gameclipscontent-d2009.xboxlive.com/xuid-MY_XUID-private/SOME_CONTENT_GUID.MP4?sv=2015-12-11&sr=b&si=DefaultAccess&sig=SIGNATURE&__gda__=GDA"
},
{
"locatorType": "Thumbnail_Small",
"uri": "https://gameclipscontent-t2009.xboxlive.com/xuid-MY_XUID-public/SOME_CONTENT_GUID_Thumbnail.PNG"
},
{
"locatorType": "Thumbnail_Large",
"uri": "https://gameclipscontent-t2009.xboxlive.com/xuid-MY_XUID-public/SOME_CONTENT_GUID_Thumbnail.PNG"
}
],
"contentSegments": [
{
"segmentId": 1,
"creationType": "UserGenerated",
"creatorChannelId": null,
"creatorXuid": MY_XUID,
"recordDate": "2021-11-27T20:24:01Z",
"durationInSeconds": 29,
"offset": 0,
"secondaryTitleId": null,
"titleId": 1814675537
}
],
"creationType": "UserGenerated",
"durationInSeconds": 29,
"frameRate": 60,
"greatestMomentId": "",
"localId": "ANOTHER_GUID",
"ownerXuid": MY_XUID,
"resolutionHeight": 1080,
"resolutionWidth": 1920,
"sandboxId": "RETAIL",
"sharedTo": [],
"titleData": "",
"titleId": 1814675537,
"titleName": "Grand Theft Auto: San Andreas – The Definitive Edition",
"uploadDate": "2021-11-27T20:26:36.0491203Z",
"uploadLanguage": "en-US",
"uploadRegion": "US",
"uploadTitleId": 49312658,
"uploadDeviceType": "Scarlett",
"userCaption": "",
"commentCount": 0,
"likeCount": 0,
"shareCount": 0,
"viewCount": 1,
"contentState": "Published",
"enforcementState": "None",
"safetyThreshold": "None",
"sessions": [],
"tournaments": []
}
GetContentEntities aggregates the localId entries from the first array that I get when I initiate the process, and then refreshes the metadata as it goes. A pretty good short-term solution, if you ask me. For some reason, this is different from contentId, and I couldn’t set the latter as a filter field (again, I am working against a very opaque API surface).
Because the metadata here is so rich, and the goal of this project is to back up all media I have from the Xbox Live network, I decided that I want to store it alongside every single file that Xbox Live gives me. As such, you will notice in the code that I am pulling the contents of each media file into an associated JSON file, retaining all the data about the tile, date of the original capture, the device type (Scarlett was the code-name for Xbox Series X).
Once I glued everything together, I was actually able to successfully back up all my media in one go. Yes, I did not have to use the app and spend months going through each capture, saving it locally.
As a side-note - what’s the deal with no longer exposing this through the web interface?
So - what is the limit for media capture storage on the Xbox Live network? Let’s look at the scoreboard, also known as “folder information”. For my screenshots (the xcs folder) I ended up using about 1.3GB, and for my videos (the xce folder) it was a bit more than 9GB:
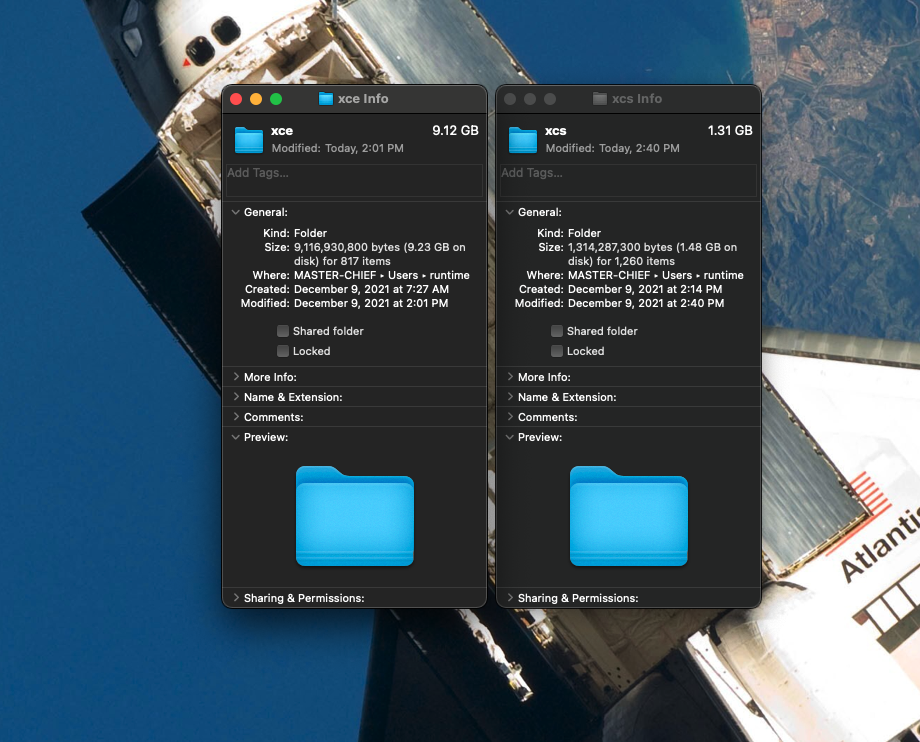
It seems that the maximum storage allowed on the Xbox Live network is about 10GB for all captures, and then it’s up to you to back everything up and free up some space. Looking at Reddit threads, it seems that the documentation on this subject is lacking, but then I discovered the official Xbox page that mentions just that.
You can upload up to 10 GB of captures to the Xbox network. Once you reach those limits, you’ll need to delete existing captures to upload new ones.
Looks like I wasn’t too far off, and manage to do all of this without ever touching OneDrive.
But I only addressed part of the problem. The second piece to this puzzle was freeing up the space from the old screenshots once I backed them up. Sure enough, there is a request for that. To delete a screenshot, I needed to send a DELETE request to:
https://mediahub.xboxlive.com/screenshots/
SCREENSHOT_CONTENT_ID
Notice that for this call it’s the contentId GUID that is used, and not localId.
For game clips (videos), the same DELETE request is sent to the gameclips endpoint:
https://mediahub.xboxlive.com/gameclips/
CLIP_CONTENT_ID
Interestingly enough, in both cases the DELETE request contains a JSON body, that looks like:
{
"headers": {
"Accept": "application/json",
"X-XBL-Contract-Version": "2"
}
}
Haven’t seen that much before, but maybe there is a service that processes this data somehow behind the scenes. I wanted to bulk-delete everything I had in the storage after I backed it up locally. For that purpose, I wrote DeleteAllMedia:
def DeleteAllMedia(token, xuid, endpoint):
content_entities = GetContentEntities(xuid, endpoint, token)
while len(content_entities.values) > 0:
for entity in content_entities.values:
success = SendDeleteRequest(token, xuid, endpoint, entity.contentId)
if success:
print(f'Successfully deleted {entity.contentId}')
else:
print(f'Could not delete {entity.contentId}')
content_entities = GetContentEntities(xuid, endpoint, token)
This function looks very similar to what I’ve done before, accepting very similar arguments, but is responsible for removing the content from the network. It constantly queries the list of available media content until there is none returned through GetContentEntities.
How do I use it to delete every single piece of content I have, though? By wrapping a DELETE request mentioned above, that accepts a content identifier as an argument:
def SendDeleteRequest(token, xuid, endpoint, content_id):
request_string = '{"headers": {"Accept": "application/json", "X-XBL-Contract-Version": "2"}}'
delete_request = request.Request(f'https://mediahub.xboxlive.com/{endpoint}/{content_id}', data = request_string.encode("utf-8"), headers = {'Authorization': token, 'Content-Type': 'application/json'})
delete_request.get_method = lambda: 'DELETE' # Yikes, but gets the job done for now.
response = request.urlopen(delete_request)
response_code = response.getcode()
acceptable_codes = [200, 202]
if response_code in acceptable_codes:
return True
else:
return False
Something to keep in mind with the function above is that you’ll notice I am checking for either a 200 or 202 HTTP response code. I haven’t seen 200 returned through this call just yet, but 202 is definitely common. All a 202 response means is that the service accepted the request for processing, which in this case makes sense - I am requesting content deletion, which is likely queued up somewhere and is not real-time (although the content does disappear instantly in my tests).
To delete both screenshots and game clips at once, I can simply call the core function twice:
DeleteAllMedia(args.token, args.xuid, 'screenshots')
DeleteAllMedia(args.token, args.xuid, 'gameclips')
That’s about it! I can now manage my Xbox media somewhat easily in one swoop instead of fiddling with the Xbox application on either a mobile device or Xbox itself.
Conclusion #
I sure wish the experience above would be easier and not force me to write Python scripts to manage media. I can, of course, work around that by integrating with OneDrive, but that workflow is also not ideal, as I would have to use OneDrive and select every capture I want to sync. I’m thinking that maybe another side project I need to build is an “Xbox Drive” that gives me a nice, Dropbox-like experience to see Xbox captures on my macOS and Windows boxes.