Building A Documentation CLI
When building documentation for your product, you will often encounter situations where you need to mix and match a bunch of content that comes from different sources. It becomes a bit more complex when you need to start dealing with different platforms, e.g. documenting APIs for Python, .NET and Java all in one place.
We do all that and more on docs.microsoft.com, where we host documentation that is both hand-written and generated automatically from code - DocFX is a very powerful and versatile system that allows you to do that with the help of pre-defined contracts for structured and unstructured content.
While one can write Markdown for their articles and overviews relatively easily in their favorite editor, they would need to use a set of disjoint tools to generate documentation for their code. In the context of DocFX, there is sphinx-docfx-yaml for Python, type2docfx for TypeScript and so on. Each of those tools has their own approach to handling inputs and outputs, that we normally delegate to individual continuous integration jobs. I wondered if there is a better way to do that for an individual that had no inherent knowledge of the underlying DocFX requirements.
This is how the idea for adg was born. My goal with this project is to build a documentation generation CLI that would allow anyone to produce great code documentation with a one-liner. It’s written entirely in Python, and generating new docs can look like this:
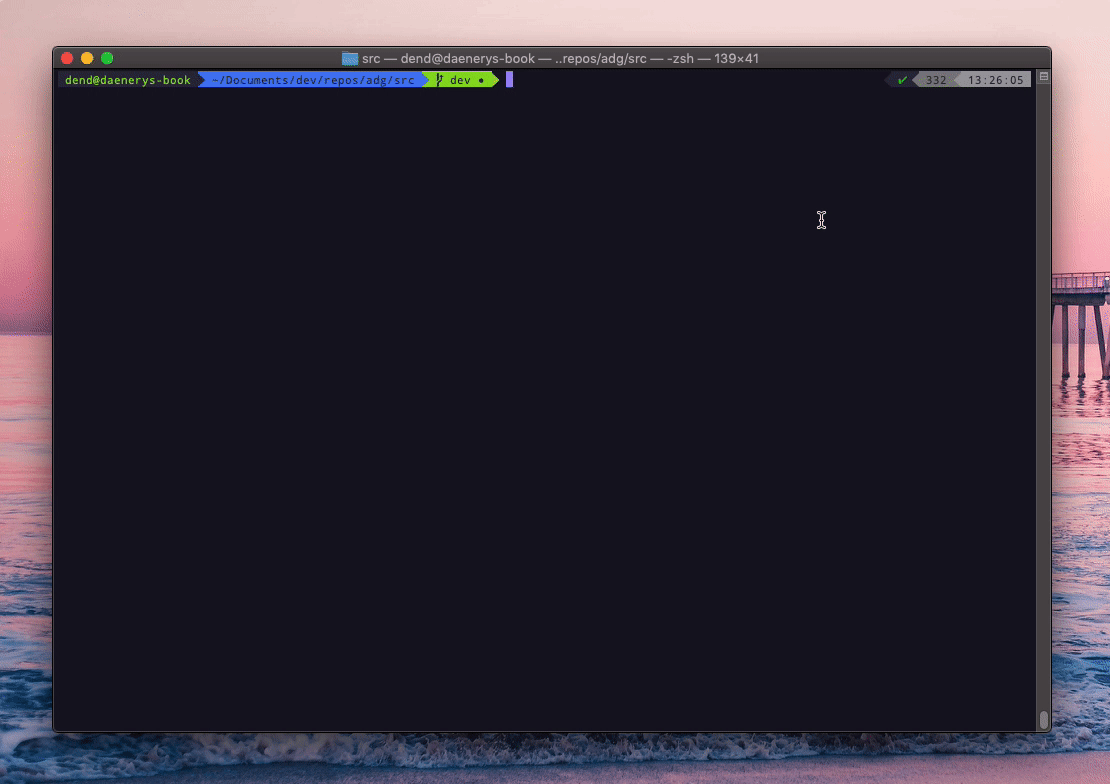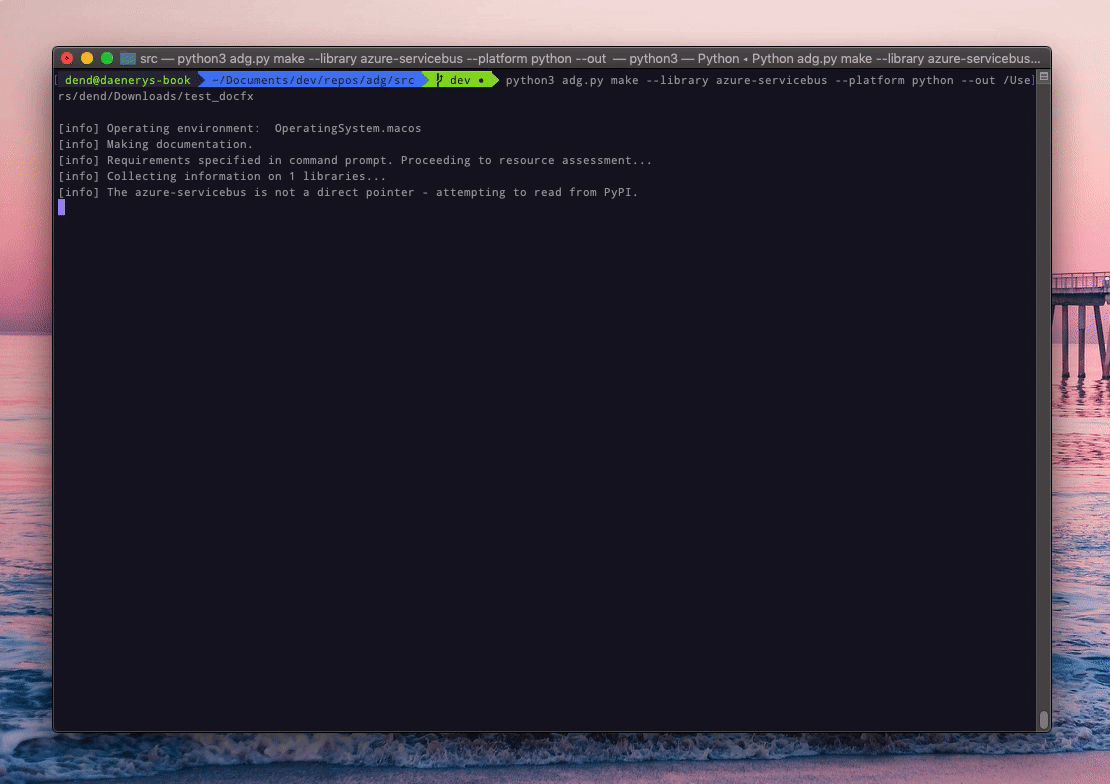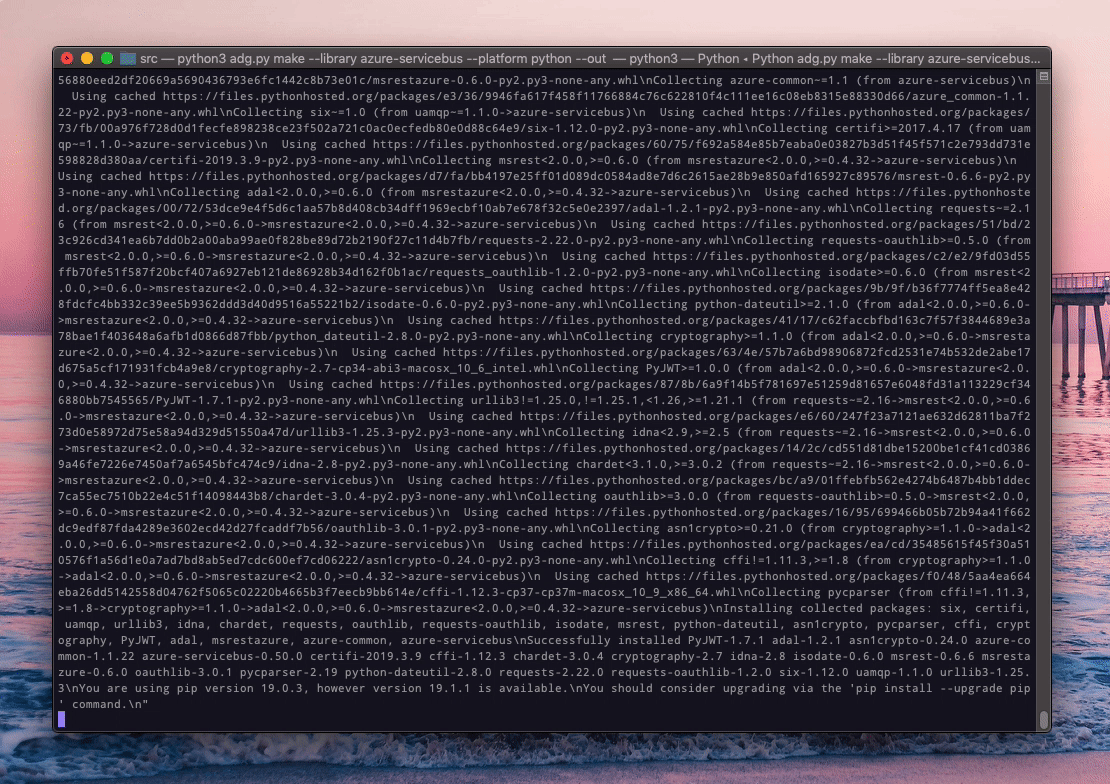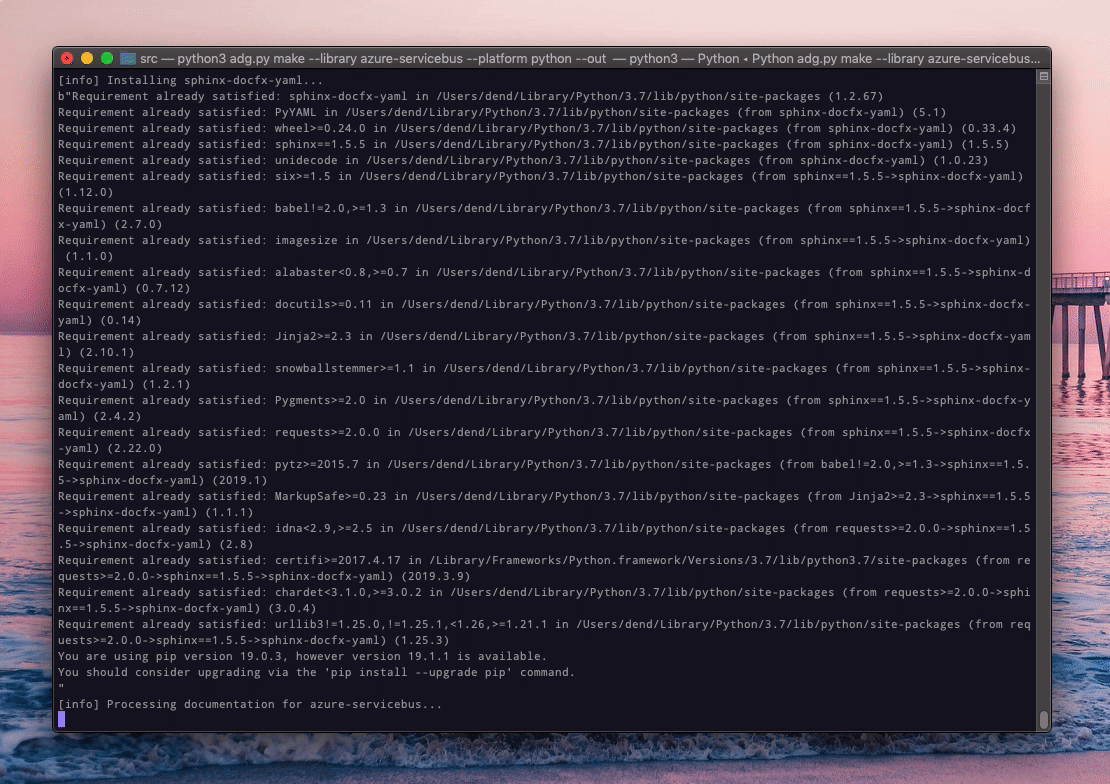
python3 adg.py make --library azure-servicebus --platform python --auto-install True
In the example above, I am using the command to generate some Python documentation with Sphinx, and then the sphinx-docfx-yaml extension to convert the produced content to a DocFX-ready format (YAML) - but you would never know that from running the command itself. So what goes on behind the scenes? Because I started working on the Python component first, that seems to be a great candidate to analyze here.
It’s worth mentioning that not all the logic is in place yet - there is a need to make sure that we account for some runtime specifics (e.g. running on Windows might be ever so different compared to running on a macOS machine), and I probably need to clean up the code. For now, we are focusing on getting things done.
In adg.py, I am using the argparse library to get the inputs from the user. I don’t want to worry too much about configuration settings or any additional files - just give the tool everything it needs to know in the terminal:
parser = argparse.ArgumentParser(description='adg - version 1.0.4-june-2019')
subparsers = parser.add_subparsers(dest="commands_parser")
make_parser = subparsers.add_parser('make')
make_parser.add_argument('--library', metavar='L', type=str, nargs='+',
help='A single or space-separated list of libraries to document.')
make_parser.add_argument('--platform', type=str, metavar='P',
help='Target platform for the documented library.')
make_parser.add_argument('--out', type=str, metavar='O',
help='Output path for the generated documentation.')
make_parser.add_argument('--auto-install', type=bool, metavar='A',
help='Determines whether helper tools need to be installed automatically.')
args = parser.parse_args()
The parameters are then validated, and passed to the command processor - an abstraction class that does some magic to figure out things like whether the right parameters were passed, or the command that needs to be executed. The command processor is pretty much just a proxy for user input to the “kernel” of the tool - coreutil.py.
coreutil.py is tasked with performing the heavy lifting. For example, it takes a library input, and attempts to install it locally to then push it through the documentation generation process - all within the process_libraries call:
class LibraryProcessor(object):
@staticmethod
def process_libraries(libraries, platform, docpath):
if (platform.lower() == 'python'):
if (PresenceVerifier.shell_command_exists('pip3')):
for library in libraries:
if (Validator.validate_url(library)):
try:
url_parse_result = urlparse(library)
domain = url_parse_result.netloc
if (domain.lower().endswith("github.com")):
print (f'[info] Getting {library} from GitHub...')
else:
print (f'[info] Getting {library} from a direct source...')
except:
print ('[error] Could not install library from source.')
# Not a URL, so we should try taking this as a PyPI package.
else:
print (f'[info] The {library} is not a direct pointer - attempting to read from PyPI.')
LibraryInstaller.install_python_library(library)
# TODO: Need to implement a check that verifies whether the library was really installed.
LibraryDocumenter.document_python_library(library, docpath)
else:
print ('[error] Could not find an installed pip3 tool. Make sure that Python tooling is installed if you are documenting Python packages.')
Similarly, it then triggers the documentation generation process through an externalized shell script (because DocFX does not have a native Python API):
class LibraryDocumenter(object):
@staticmethod
def document_python_library(library):
process_result = subprocess.run(['pip3', 'list',], stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
if 'spinx-docfx-yaml' in process_result.stdout.decode('utf-8'):
# We have the extension (https://github.com/docascode/sphinx-docfx-yaml) installed
print ('[info] The sphinx-docfx-yaml extension is already installed.')
else:
print ('[info] Installing sphinx-docfx-yaml...')
process_result = subprocess.run(['pip3', 'install', 'sphinx-docfx-yaml', '--user'], stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
ConsoleUtil.pretty_stdout(process_result.stdout)
print (f'[info] Processing documentation for {library}...')
process_result = subprocess.run(['sh', 'scripts/pythondoc.sh', 'dtemp/packages', library.replace('-','/')], stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
ConsoleUtil.pretty_stdout(process_result.stdout)
I am not yet sure whether running the shell script is the ideal approach here - it is effectively spawning another process, and I am yet to check out execv (thank you to Brett Cannon for pointing me in this direction). It gets the job done, though! What the script hides behind the scenes is a set of commands that:
- Bootstrap a temporary Sphinx documentation project.
- Generate native Sphinx documentation based on the installed Python package.
- Convert the Sphinx output to DocFX-compatible YAML.
Normally, you would need to run this all yourself, but now adg does it for you. A similar approach would apply to other platforms, like Java, .NET and TypeScript (among others), where adg is tasked with not exposing the user to the complex set of tools and commands and modifications, rather than replace those.