Tracking Instagram Hashtag Popularity
Table of Contents
I previously talked about connecting to Instagram without the browser as part of a little hobby project I am working on. Another component of this project involves tracking the popularity of individual hashtags on Instagram, and how those grow over time. There are two approaches that I will describe here, each with its own merits, that can solve the problem.

NOTE: This is a just-for-fun project - no private information is collected, or shared through it.
Components Involved #
Before we get into the more in-depth details, it’s worth covering the components that we will use in the project:
| Component | Description |
|---|---|
| Python | The programming language used for the project. It’s cross-platform, flexible, and has plenty of supporting libraries that can help us accomplish tasks quickly. |
| Elasticsearch | The data engine backing the information we are analyzing. It’s useful to have a local copy of the information you want to process, as well as a more date/time-based snapshot. |
| Kibana | A visualization and data exploration engine on top of Elasticsearch. |
| elasticsearch-py | A Python-based client for Elasticsearch, that implements a lot of the necessary plumbing required for us to operate. |
| Selenium | Tool used to automate website testing and verification. |
Selenium is only need for the first potential implementation, so if for some reason you are not really enjoying the idea of using an automation tool to collect the data, skip right ahead to the second implementation. You might need it eventually, but that just implies that you can install it later whenever that need arises.
In this article I am also making the frivolous assumption that you have some familiarity with how to install Elasticsearch and Kibana on your machine, you already have Python configured and feel comfortable with pip.
Baseline for the data analysis #
Starting up, you need to know what you will be collecting, and that is historical data on hashtags - there is a static definition somewhere that defines the hashtags that need to be tracked, and there is a an engine that reads that information in, queries Instagram and stores the information in the designated data store. That historical data can later be analyzed through the visualization engine.
Aproach 1: Using Selenium to read page contents #
This is by far the most primitive approach to the problem, but can work if you have access to a browser engine (might not always be the case on a server).
Every tag on Instagram has a dedicated page. In the example below, I am looking at #earthfocus and #instagood.
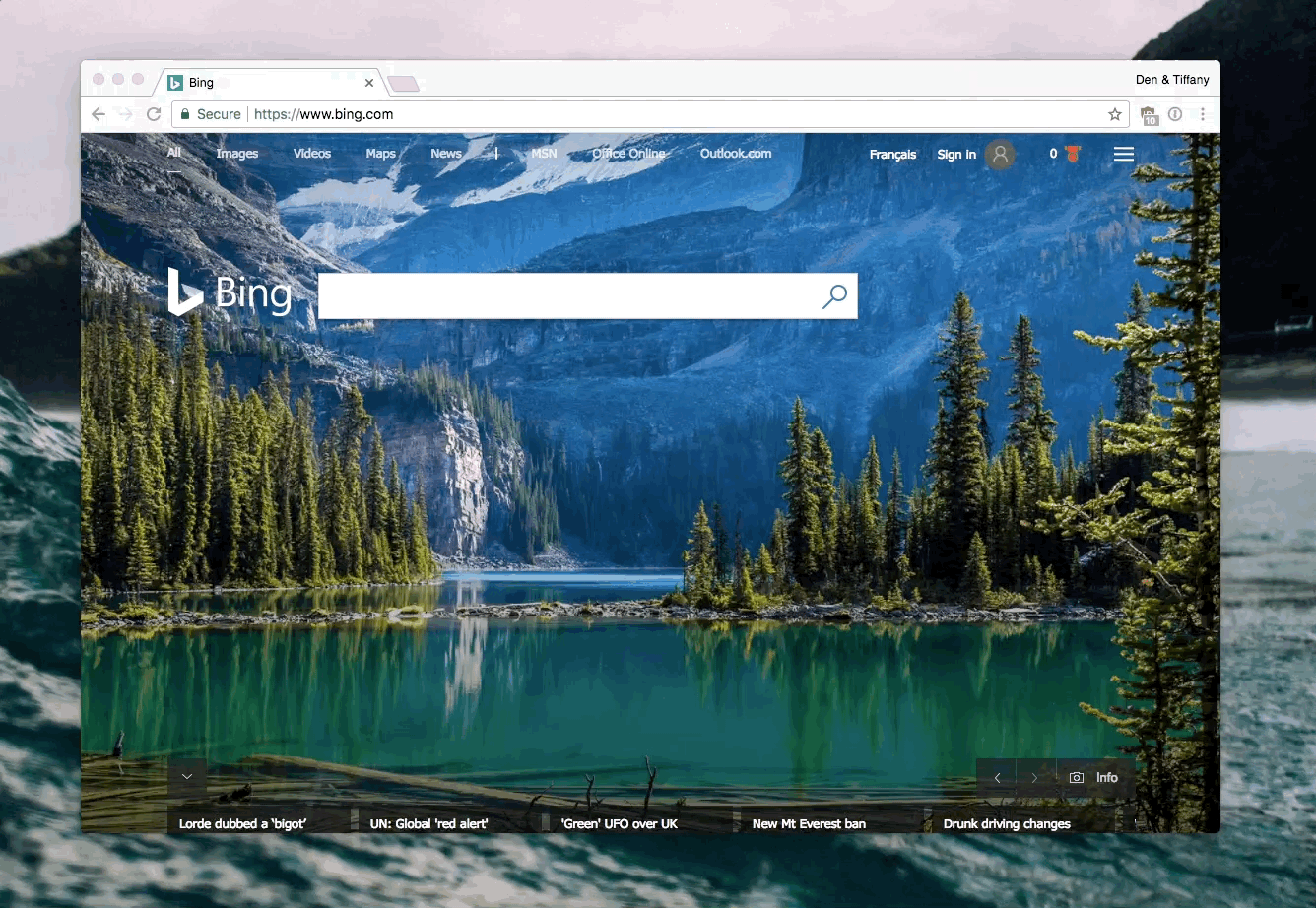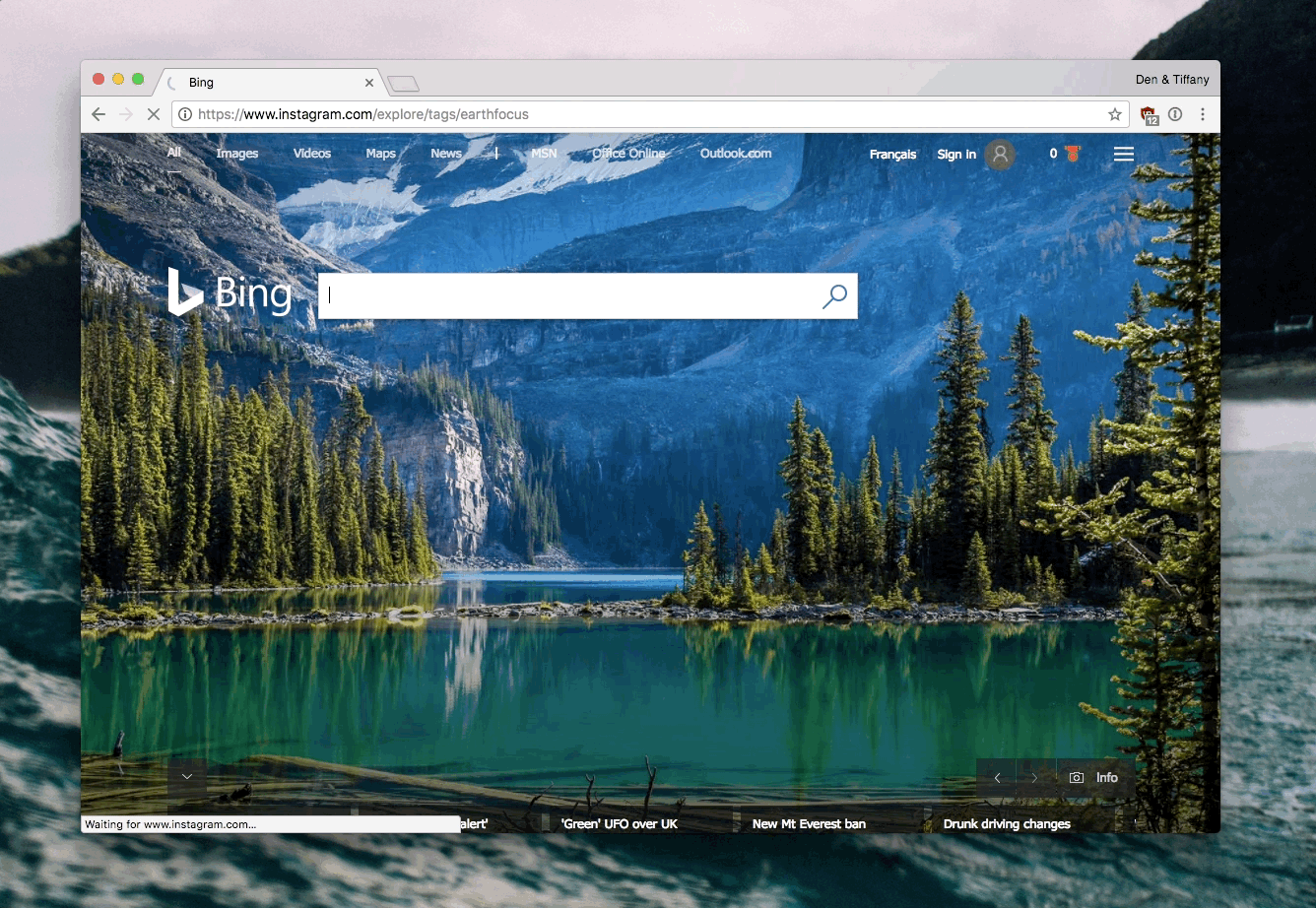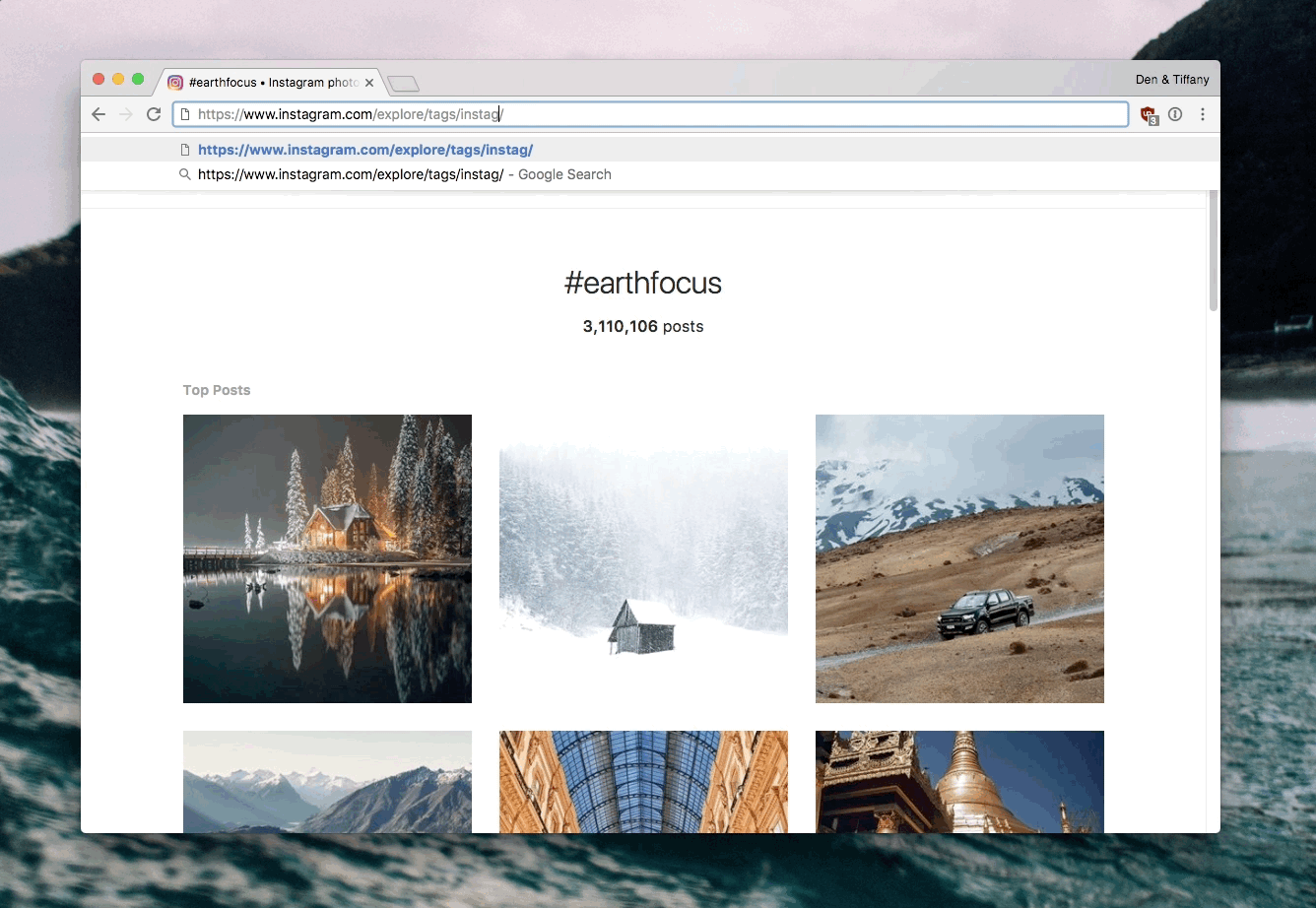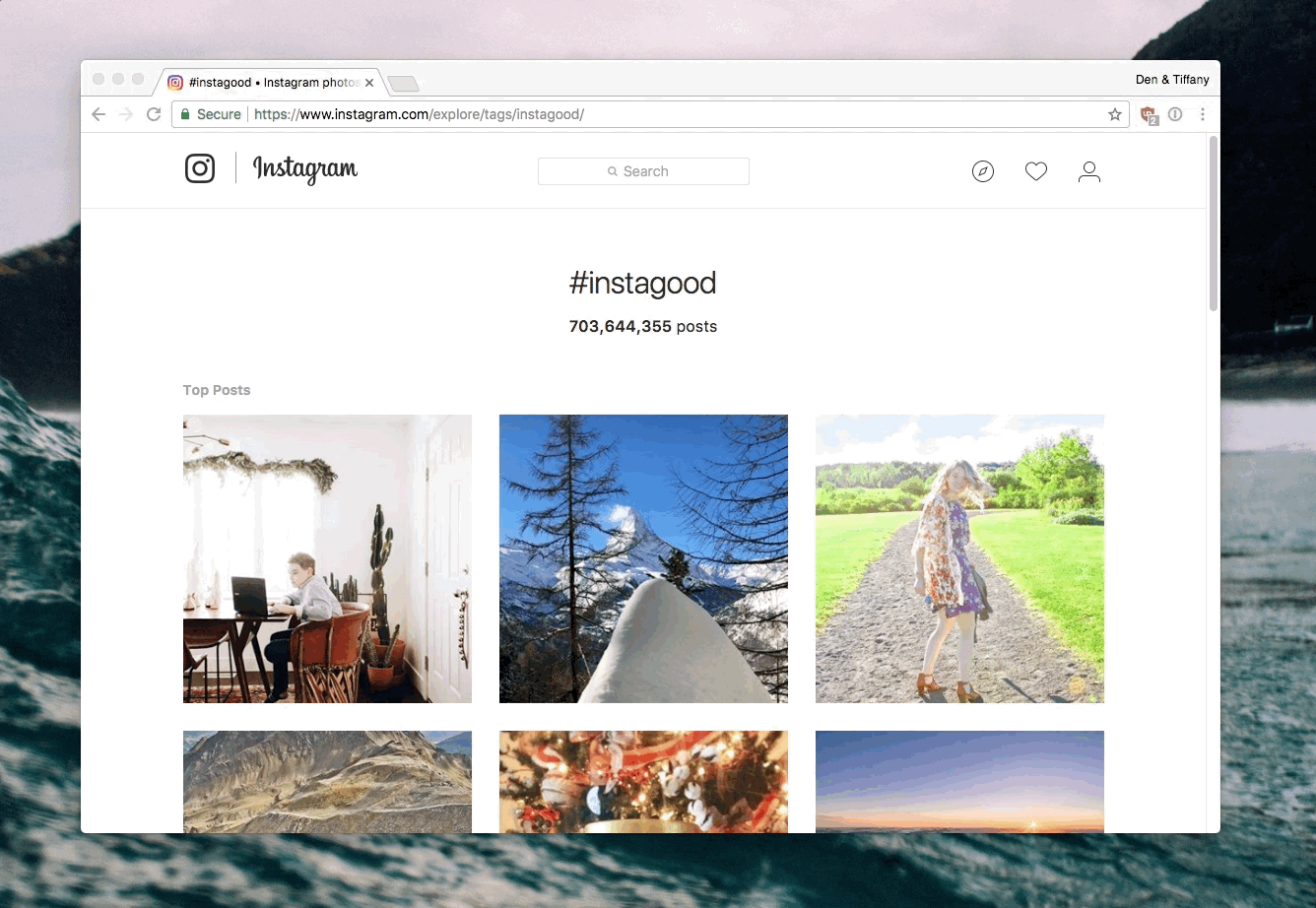
Notice that there are two pieces available on the page - the count of photos that are tagged with a specific hashtag, and of course the 9 top posts with the given hashtag. We need to read those in.
So let’s say that we have a number of hashtags that need to be tracked - we will put them in a text (.txt) file on disk, somewhere close to the script, e.g. in a /data folder. Its contents literally should resemeble something like:
travelphotography
travel
instagood
geometry
minimal
beautiful
perspective
architectures
city
geometric
cities
style
primeshots
urban
building
The Instagram hashtag pages have the following URL pattern:
https://www.instagram.com/explore/tags/{HASHTAG}/
As long as we can read in individual tags, we can substitute them in the URL and get the page contents. I created an Ingestor class that is tasked entirely with getting information from different tag pages:
# Imports
from datastore import *
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import urlparse
import os, sys
class Ingestor():
work_root=''
instagram_username=''
instagram_password=''
instagram_login_url = 'https://www.instagram.com/accounts/login/'
driver = None
datastore = None
def __init__(self, username='',password=''):
self.instagram_username = username
self.instagram_password = password
self.work_root = os.path.dirname(os.path.abspath(__file__))
print "INFO: ", "Absolute script path: ", os.path.abspath(__file__)
chromedriver = os.path.join(self.work_root, 'drivers/chromedriver')
print "INFO: ", "Path to driver: ", chromedriver
os.environ["webdriver.chrome.driver"] = chromedriver
self.driver = webdriver.Chrome(chromedriver)
self.datastore = DataStore()
Some things to call out in terms of class-wide variables:
| Variable | Description |
|---|---|
work_root |
The path to the directory where the script is executing. Helpful to obtain the necessary tag data later. |
instagram_username |
Like I mentioned earlier in the post, some actions that might be useful later require authentication. For that to happen, we need to have the Instagram username handy. |
instagram_password |
Fairly self-explanatory, and associated with the username above. |
instagram_login_url |
The URL where the user can go and perform a log in. |
driver |
The web browser automation driver. |
datastore |
Elasticsearch connector class that will help us store hashtag data. |
When the class is initialized, the __init__ call is triggered. Within it, I am reading in the username and password the developer passed into the constructor, and storing them locally. The work_root is assigned a path to the directory where the script is executed. For web browser automation, I am using ChromeDriver, which is copied locally, and driver is instantiated to a new web driver instance, with the path to the locally-available ChromeDriver. The datastore variable is instantiated to a new DataStore instance, that is responsile for putting data into Elasticsearch:
from datetime import datetime
from elasticsearch import Elasticsearch
class DataStore():
es_instance = None
def __init__(self):
self.es_instance = Elasticsearch()
def store_tag_popularity(self,tag='', tag_posts=0, tag_popular_posts=''):
self.es_instance.indices.create(index='tag_popularity',ignore=400)
self.es_instance.index(index='tag_popularity',doc_type='tag', body={"tag_name": tag, "tag_posts": tag_posts, "timestamp": datetime.now(), "tag_popular_posts": tag_popular_posts})
I should note, while we are on the topic of the data storage class, that I am not passing any information to the class on how to connect to my Elasticsearch instance. That is because it defaults to the initial connection, that is https://localhost:9200. If you have a remote Elasticsearch instance, you will obviously want to tweak this declaration.
store_tag_popularity is responsible for getting the tag name, number of posts and an array of Instagram URLs to the most popular images for the currently inspected tag.
But back to Ingestor.
The function that gets tag data is get_tag_data:
def get_tag_data(self,tag_file=''):
# Get the path to the data file.
tag_file_input = os.path.join(self.work_root, 'data/', tag_file)
with open(tag_file_input, 'r') as input_tags:
# Read in the list of tags that we need to get the popularity for.
tags = input_tags.readlines()
for tag in tags:
# Clean-up the tag from new-line characters.
working_tag = tag.replace('\n','')
print "INFO: ", "Getting information for tag: ", working_tag
self.driver.get("https://www.instagram.com/explore/tags/" + working_tag)
number_of_photos_tagged = 0
# Attempt to get the number of images with a number of tagged posts.
try:
number_of_photos_tagged_raw = self.driver.find_element_by_xpath("//*[@id='react-root']/section/main/article/header/span/span")
# If data is obtained, we need to replace the comma character from the string to make it a number.
if number_of_photos_tagged_raw:
number_of_photos_tagged = number_of_photos_tagged_raw.text.replace(',','')
# If we could not get the number of tags, we still want to go on.
except:
pass
# Show the user a warning that we could not get the number of photos tagged.
if number_of_photos_tagged == 0:
print "WARNING: ", "No tagged number for ", working_tag
print "INFO: ", "Tagged photos: ", number_of_photos_tagged
# Construct an array that will hold popular photo URLs.
tag_popular_posts = [None] * 9
increment = 0;
# 3 columns, 3 rows - iterate through each to get the URLs to individual top posts. This is typically the case.
try:
for row in range (0,3):
for column in range(0, 3):
target_row = str(row + 1)
target_column = str(column + 1)
top_photo = self.driver.find_element_by_xpath('//*[@id="react-root"]/section/main/article/div[1]/div/div[' + target_row + ']/div[' + tar
tag_popular_post = top_photo.get_attribute("href")
tag_popular_posts[increment] = tag_popular_post
increment = increment + 1
print "INFO: ", "Popular photo: ", tag_popular_post
print "INFO: ", "Existing photo array: ", tag_popular_posts
# Sometimes this fails (e.g. not enough posts) - still, the show must go on.
except:
pass
if all(v is None for v in tag_popular_posts):
print "WARNING: ", "No popular photos for ", working_tag
else:
# Store the data we just obtained in Elasticsearch.
self.datastore.store_tag_popularity(tag=working_tag,tag_popular_posts=tag_popular_posts, tag_posts=long(number_of_photos_tagged))
I tried to keep the comments in the snippet above pretty concise and to-the-point, so a lot of the code should be relatively self-explanatory. We are loading a page and trying to read in the number of top tagged posts. Sometimes, we need to create handlers for exceptions that arise from conditions out of our control.
One example of that, explicitly fenced-off above, is the case when a hashtag does not have the number of tags exposed. As an example, say we go to #newyear:
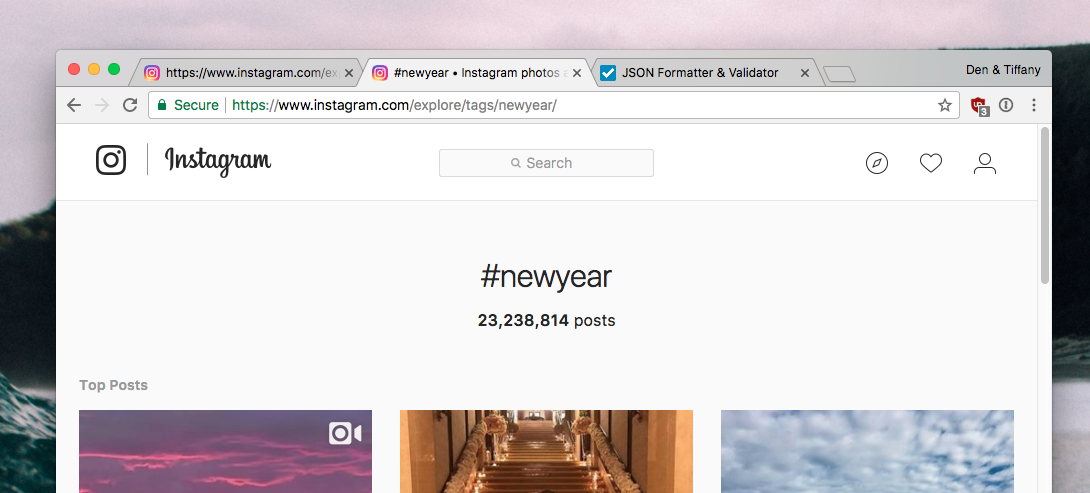
Now go to #newyears:

Notice that the latter does not have the number of posts tagged with the hashtag? For some reason, Instagram restricts certain tags to have all top-posts only, and no number of tagged posts available in the page itself. Coincidentally, this number is displayed in the Instagram search results:

Once you test the Ingestor code above, you will notice that for each tag, you will get a time/date-based snapshot - with the name, number of tagged posts, and top 9 URLs. Let’s look into how we can take this approach and make it more reliable.
Approach 2: Using JSON and query parameters #
Reading data through Selenium and XPath (yikes) is somewhat unreliable. So, of course, there is a better way to do it, that I found out about right after I wrote the automated reader. That is - through a query parameter in the URL. Apparently Instagram exposes a JSON model for a significant chunk of tag and user data, that does not require authentication. All that needs to be done is appending a ?__a=1 which I can only assume stands for automated=1 that makes the output machine-readable.
NOTE: Here is the kicker - while more “machine-readable” and all-around good-to-use method, you will also likely get quickly throttled by pinging this API frequently, and get an RST packet, which will reset the connection to the server and block the script. Ultimately, I do not recommend sending retries, because that’s Instagram’s way of saying “alright, you’re clearly not intended to use this frequently, go away”.
The working URLs would have a structure similiar to this:
https://www.instagram.com/explore/tags/{HASHTAG}/?__a=1
Based on the information we get through the provided JSON, we can build a much more elegant (and speedier) function:
def get_tag_data_json(self,tag_file=''):
tag_file_input = os.path.join(self.work_root, 'data/', tag_file)
with open(tag_file_input, 'r') as input_tags:
tags = input_tags.readlines()
for tag in tags:
working_tag = tag.replace('\n','')
print "INFO: ", "Getting information for tag: ", working_tag
url = "https://www.instagram.com/explore/tags/" + working_tag + "?__a=1"
response = urllib.urlopen(url)
data = json.loads(response.read())
number_of_photos_tagged = 0
# We already have the path to the tag, so we just refer it as if
# we are handling an array.
try:
number_of_photos_tagged = data["graphql"]["hashtag"]["edge_hashtag_to_media"]["count"]
except:
pass
if number_of_photos_tagged == 0:
print "WARNING: ", "No tagged number for ", working_tag
print "INFO: ", "Tagged photos: ", number_of_photos_tagged
tag_popular_posts = [None] * 9
try:
for counter in range (0,9):
# The code is the unique Instagram ID for the photo - we simply concatenate it with
# an Instagram base URL.
tag_popular_post = "https://instagram.com/p/" + data["tag"]["top_posts"]["nodes"][counter]["code"]
tag_popular_posts[counter] = tag_popular_post
print "INFO: ", "Popular photo: ", tag_popular_post
print "INFO: ", "Existing photo array: ", tag_popular_posts
except:
pass
if all(v is None for v in tag_popular_posts):
print "WARNING: ", "No popular photos for ", working_tag
else:
self.datastore.store_tag_popularity(tag=working_tag,tag_popular_posts=tag_popular_posts, tag_posts=long(number_of_photos_tagged))
As you can see from the function above, there really is not a lot different between this implementation and the previous one, other than the fact that instead of parsing HTML we are actually parsing JSON, that is less likely to break our system if something changes in the view, or how Instagram tags their content.
Running the script #
We want the data to be collected more-or-less continuously - there are several ways to do that, including re-running the script upon termination:
import os
while True:
os.system('python quickstart.py')
Or, since we own the entire script set, we can just call it internally, as such:
from ingestor import *
ingestor = Ingestor(username='',password='')
while True:
ingestor.get_tag_data_json(tag_file='tags.txt')
Leave this running for an hour or two, and you will collect enough data to perform some basic hashtag growth analysis!
Looking at the data #
Once you collected enough data, you can fire up your browser and launch Kibana:
https://localhost:5601
Go to Management > Index Patterns and define a new index pattern that needs to be tracked:
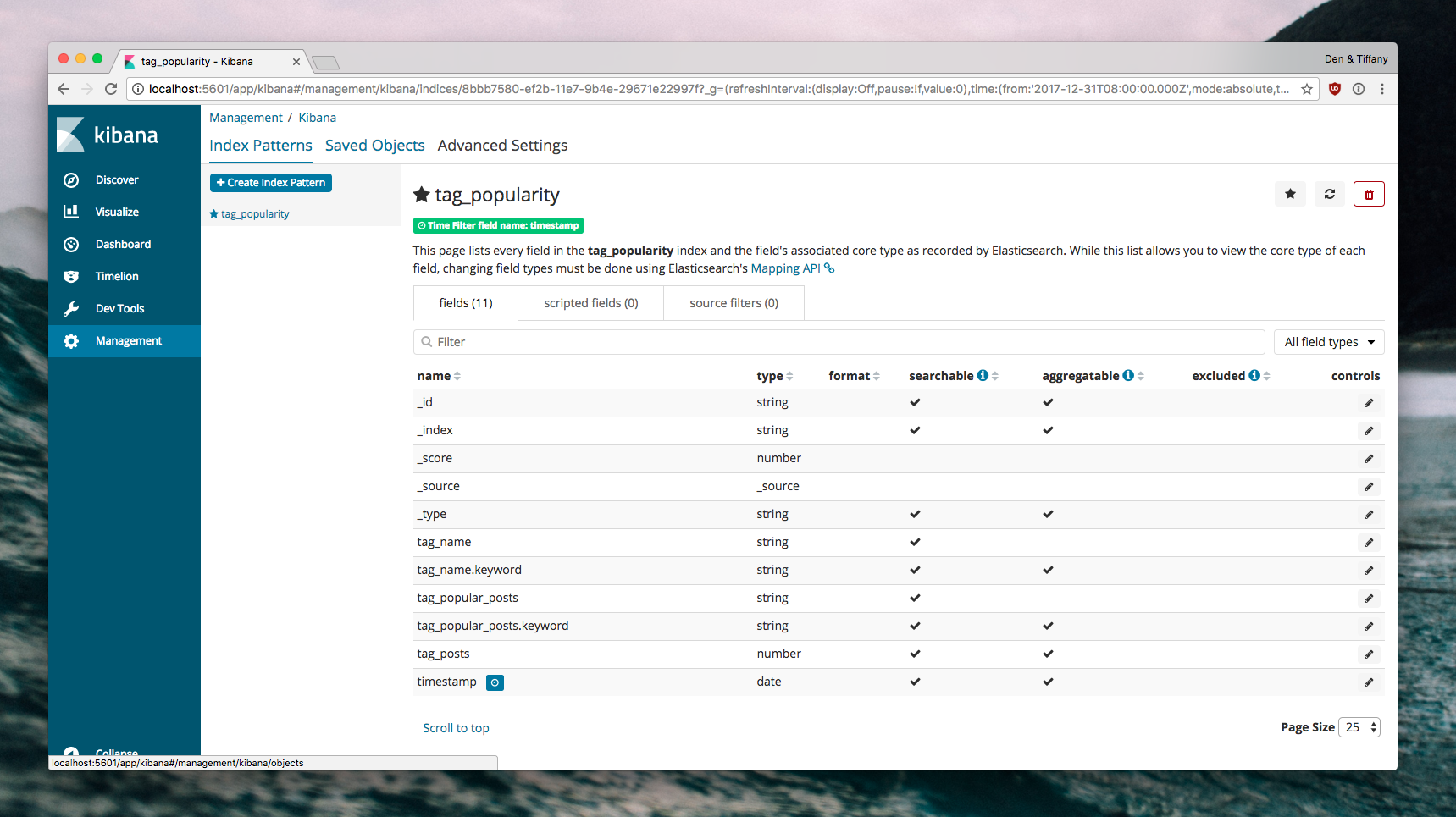
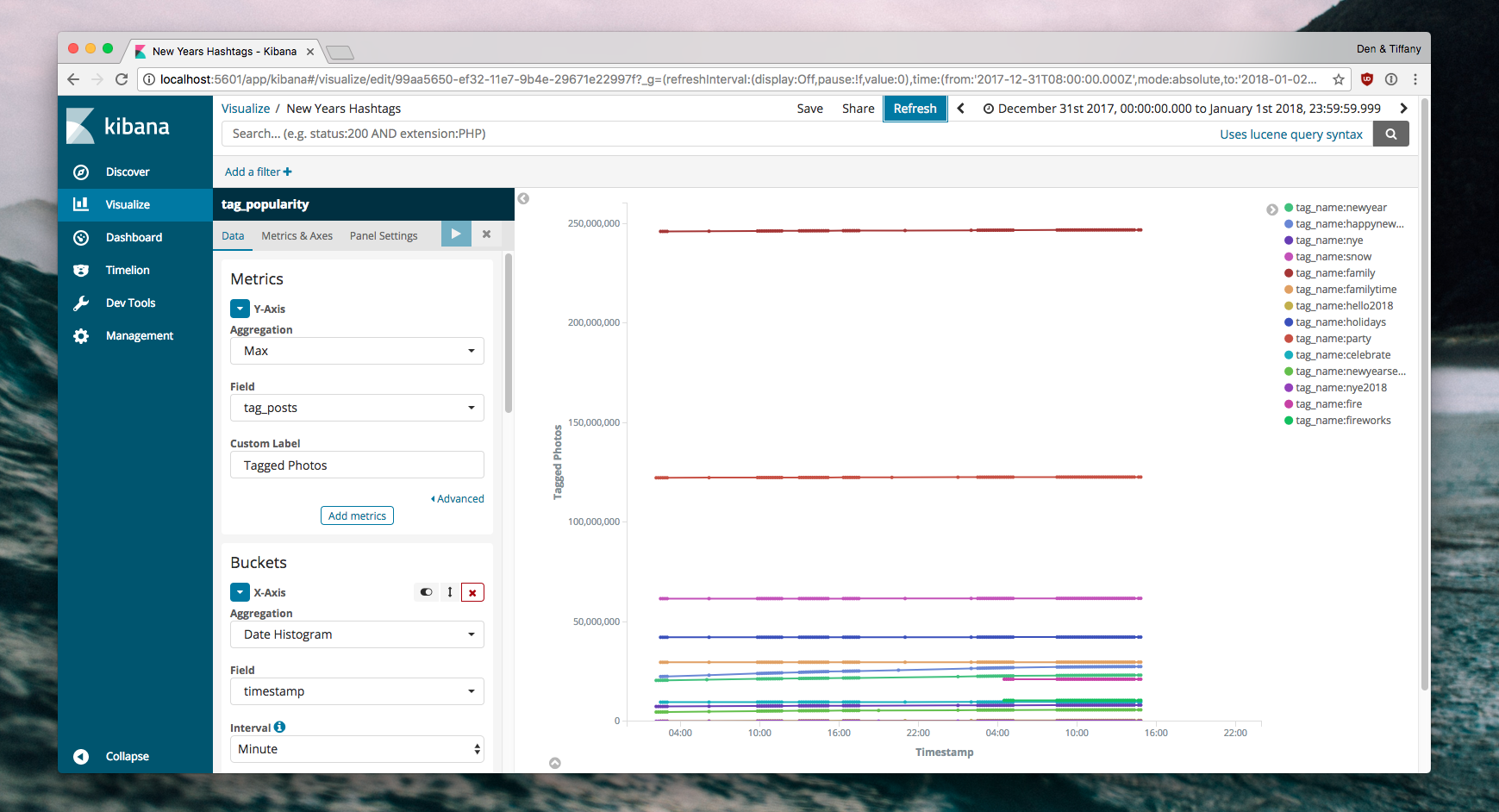
Now, go to Visualize. You can create a new Line Chart, with the Y-axis representing the number of posts for a certain tag. Given that we are aggregating at random time intervals (depending on how quickly the script runs), we can use the Max value as the source of truth for any given snapshot:
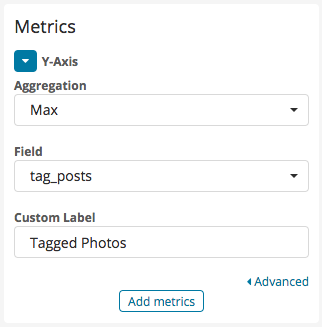
On the X axis we will present the time value:
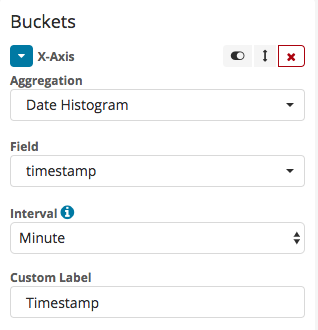
In addition, you need to add sub-aggregations, that will represent individual tags - that can be done by adding a Split Series component, with tag_name:{TRACKED_HASHTAG} as the value of the filter:
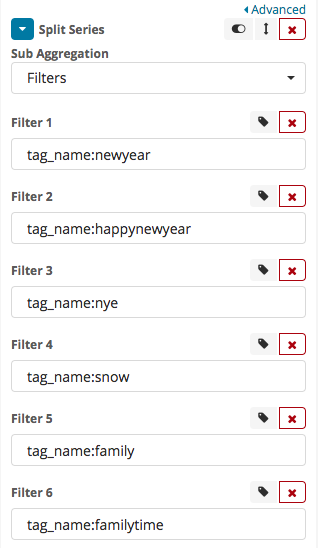
Once set up, save the visualization - and now you will see how the hashtags on Instagram grow!
With a bit of extra effort, we can easily containerize the Elasticsearch, Kibana and ingestion instances and deploy them to the cloud for a more continuous data capture mechanism.