Progress On OpenSpartan - Profile And Match Tracking
A few more weeks went by since my last blog post on OpenSpartan and I wanted to share some progress on the Halo Infinite companion app that I am building. Transparently, the bulk of the time was spent dealing with data storage logic. One of the things that I am trying to do is make sure that I minimize the amount of API calls being made to Halo Infinite services. To do that, things like match records, which require most API calls to get the full set of insights for, are stored alongside all other player metadata in a local SQLite database.
Right away I ran into some problems. There are two different APIs to get player match overview - one that returns numeric representations of how many matches a player has participated in, and another that returns individual match details in paginated format (that is - request some, then move the “cursor” a few records forward, then request more matches from that specific starting point, repeating until you hit the end). I incorrectly assumed that the first endpoint that presents basic match counts is one hundred percent accurate. My application logic for taking a full snapshot of match records was:
- Get match counts.
- Compare the counts with number of records in the SQLite database.
- If API-sourced counts are higher than the number of local records, request the last N matches, where N is the difference between local and remote match counts.
As it turns out, the API that provides counts somehow skips over a few dozen matches on my own profile. I am not sure how widespread this behavior is, but I very clearly saw that I can’t trust the returned number to be representative of all matches played. So, instead, I had to rebuild the logic as:
- Using the endpoint that returns matches in a paginated format, get all match IDs until exhaustion (no more matches left to page through).
- Compute the delta between match IDs acquired through pagination and match IDs already in the local database.
- For the match IDs that are not in the database, acquire match data.
It turned out that this approach worked relatively well, the main trade-off being that every time OpenSpartan starts, it needs to do a match cross-check to ensure that all remote matches also exist in the database.
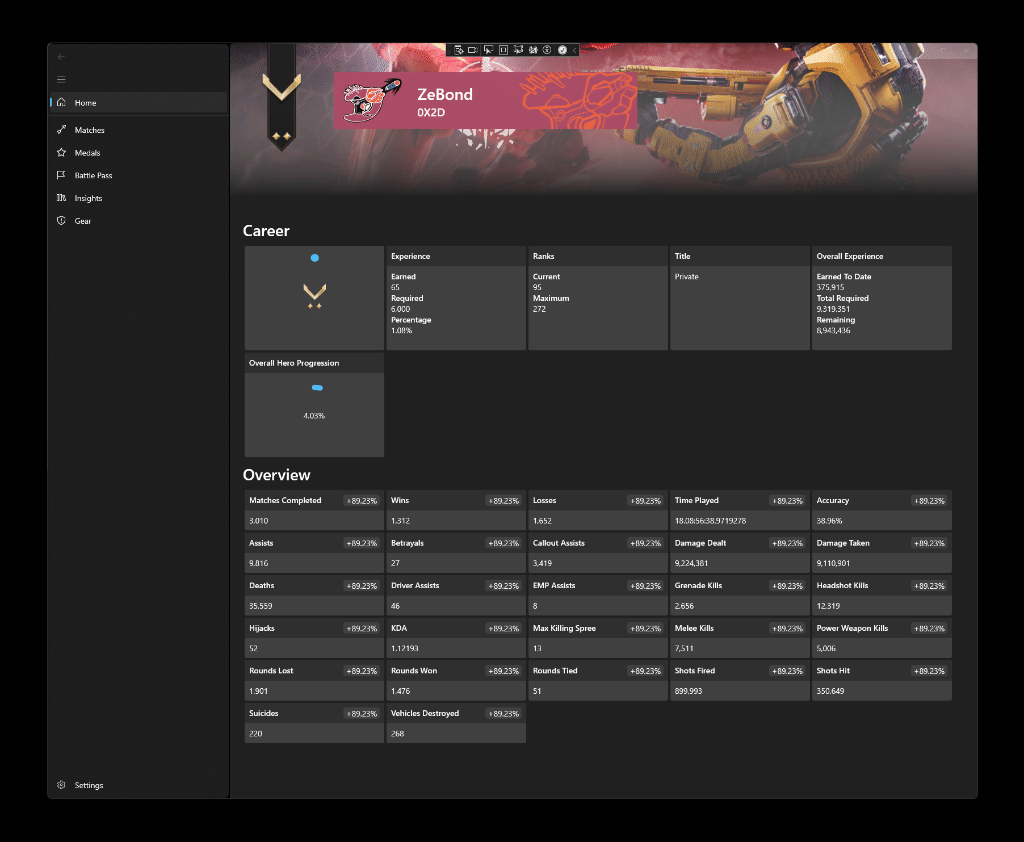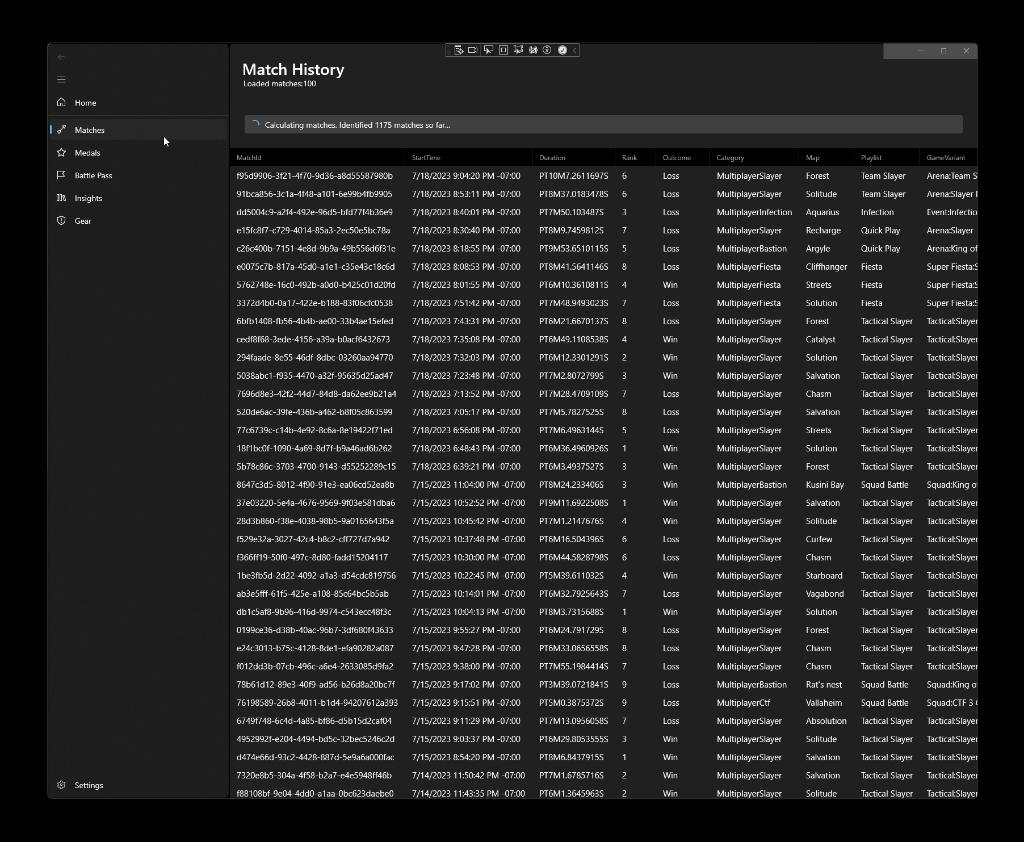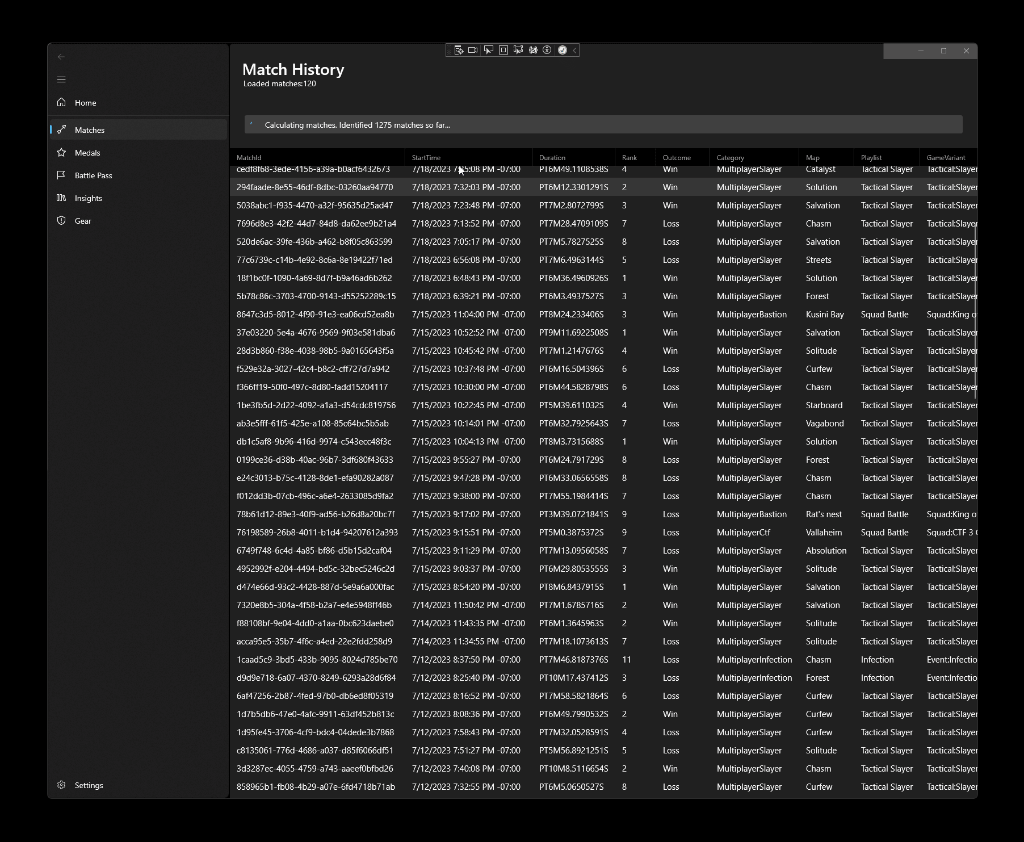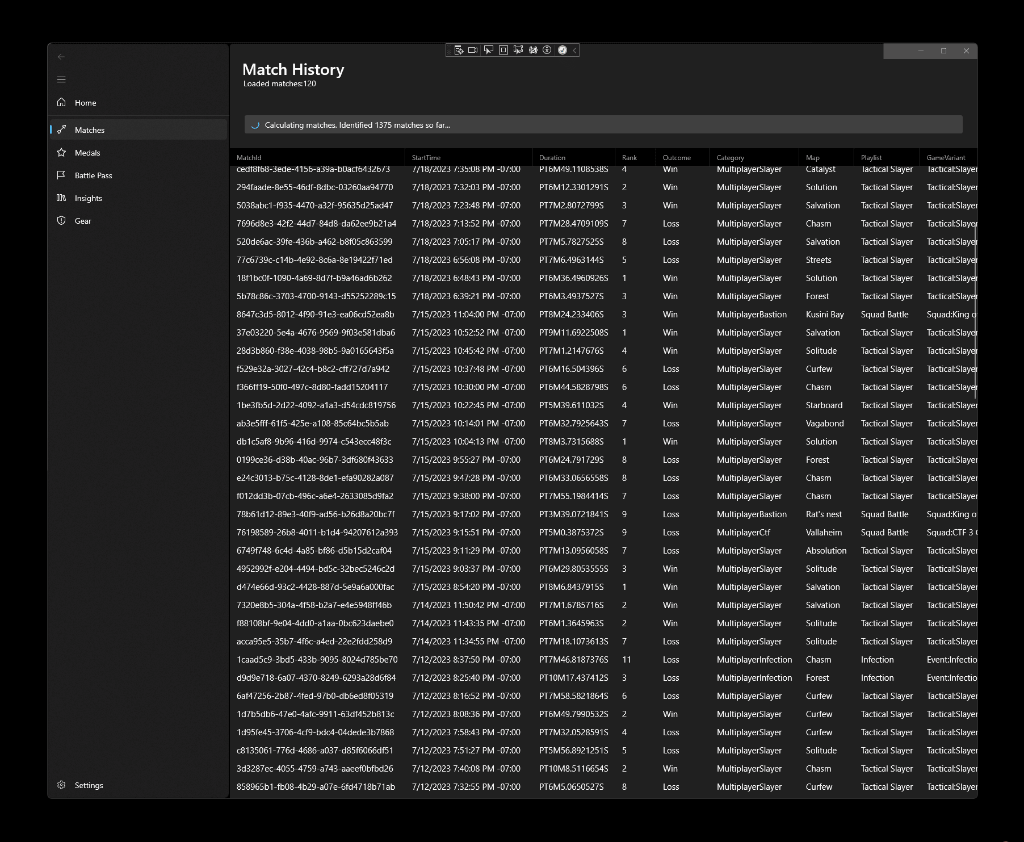
The loading indicator at the top of the match view shows the progress in computing the delta. That being said, for players that have quite a few matches played the computation might take some time as it’s done in sequenced batches of twenty five records per API call - for someone with 10,000 matches that would mean a whole 400 API calls to get the full list. The first “hydration” (population of the database with data) will take some time, but that would be suboptimal to do on every application load. So instead, once the records are populated in the local SQLite database, they can be retrieved right away when the application starts. All match data, along with map, playlist, and game engine variant data is already captured locally, so it doesn’t need to be retrieved from the server.
Just as I talked in the last blog post, my goal is to make it extremely easy to analyze your own data locally, and SQLite makes it a breeze, both from my own implementation as well as long-term maintenance perspectives. Once you have match, service record, and asset information in your database, you can break out of the bounds of OpenSpartan and reference it anywhere else you see fit, like a Jupyter notebook with more fancy charts and tables, as the raw data for your own player is all there.
With the current work, I added another component to the stack - the Windows Community Toolkit. From it, two components made my life significantly easier: DataGrid and IncrementalLoadingCollection (on the latter - shout-out to Michael Hawker for helping discover and integrate). DataGrid is used to render the match data, and with IncrementalLoadingCollection I don’t need to override the ScrollViewer in the grid to track when new data needs to be dynamically loaded.
In my explorations, I’ve also tried using Entity Framework Core instead of Microsoft.Data.Sqlite to talk to my SQLite database but ran into way too many issues around the existing classes that represent API entities returned by Halo Infinite services - they would need to be heavily re-architected to fit a model where they also represent tables and I wanted to keep things lean and simple, hence all of the querying is done directly through parameterized SQL queries stored in .sql files inside the project.
For now, the Minimum Viable Product (MVP) stage is progressing - I got the core pieces in place and now adding more rich metadata (medals and battle pass progress are next in line).
As an added bonus, I discovered a memory leak coming from navigation activity between different pages in the window, but that’s going to take some time to unravel, and maybe something to chat about in the next installment of this impromptu progress report.
If you want to be among the first people to try the app when it hits production, go to the OpenSpartan homepage and put your email in the waitlist form.