Building A Centralized Samples Experience At Microsoft
Table of Contents
One of the biggest projects I’ve had the honor of being a part of has shipped a couple of days ago - docs.microsoft.com/samples. If you haven’t read the announcement blog post, I recommend you start there.
Table of contents #
- Inception
- Looking back
- First steps
- Improving the experience
- Published pages
- Automating releases
- Stack
- Conclusion
Inception #
When we started working more in-depth on developer experiences, we realized that there are too many disjoint pages out there that provide an aggregation of code samples (and we ship thousands of samples that span hundreds of teams). It was pretty obvious that we needed to do something about that and consolidate this effort under a more modern “umbrella”. We asked ourselves - what if we presented all code samples within one search and discovery engine, powered by GitHub, as well as take advantage of the rich capabilities provided by docs.microsoft.com in terms of content hosting and rendering? This would make it much easier for our customers to find the code they need to get started with our services quickly and efficiently, with the added benefit of making the maintainers’ lives easier when it comes to keeping their samples in good shape.
We established the following guiding principles, that would help us define what we needed to build:
Intuitive and discoverable experience #
Whatever we build needs to be simple that can get customers on their way within seconds. We wouldn’t want someone to spend time figuring out how to search for code samples. Their focus is on getting the code, so we wanted to get the relevant content to the front and get out of the way.
Powered by standard tooling and infrastructure #
When it comes to conventions and standards, there are many that are already available and adopted by a broad community of developers and GitHub contributors. We didn’t want to come up with a bunch of custom workflows that are unknown to someone working in the open source software space. We focused on a service developers love - GitHub. All samples would live there, and we’d do our best to connect to the service in a way that feels natural for a developer in that ecosystem.
Comprehensive #
There are so many products and services within the company, that we simply could not create something that would cover just one vertical. This needed to be an experience that is inclusive of the various product groups.
Encourage best practices in open source samples #
The approaches we take to sample discovery and indexing should positively influence the company in terms of its ability to contribute to open source samples. Similarly, we wanted to help grow this culture externally. Good and extensive content that allows users to get started, responsiveness to issues and pull requests and others were among the requirements we established to grow the site.
Automated #
Maximize automation to ensure that developers can focus on their samples and not on processes behind publishing and validating those. When building a piece of code that showcases a product or service, the last thing the developer wants to do is spend time debugging the code sample indexing service.
We believe that these principles were formalized in the new samples browser.
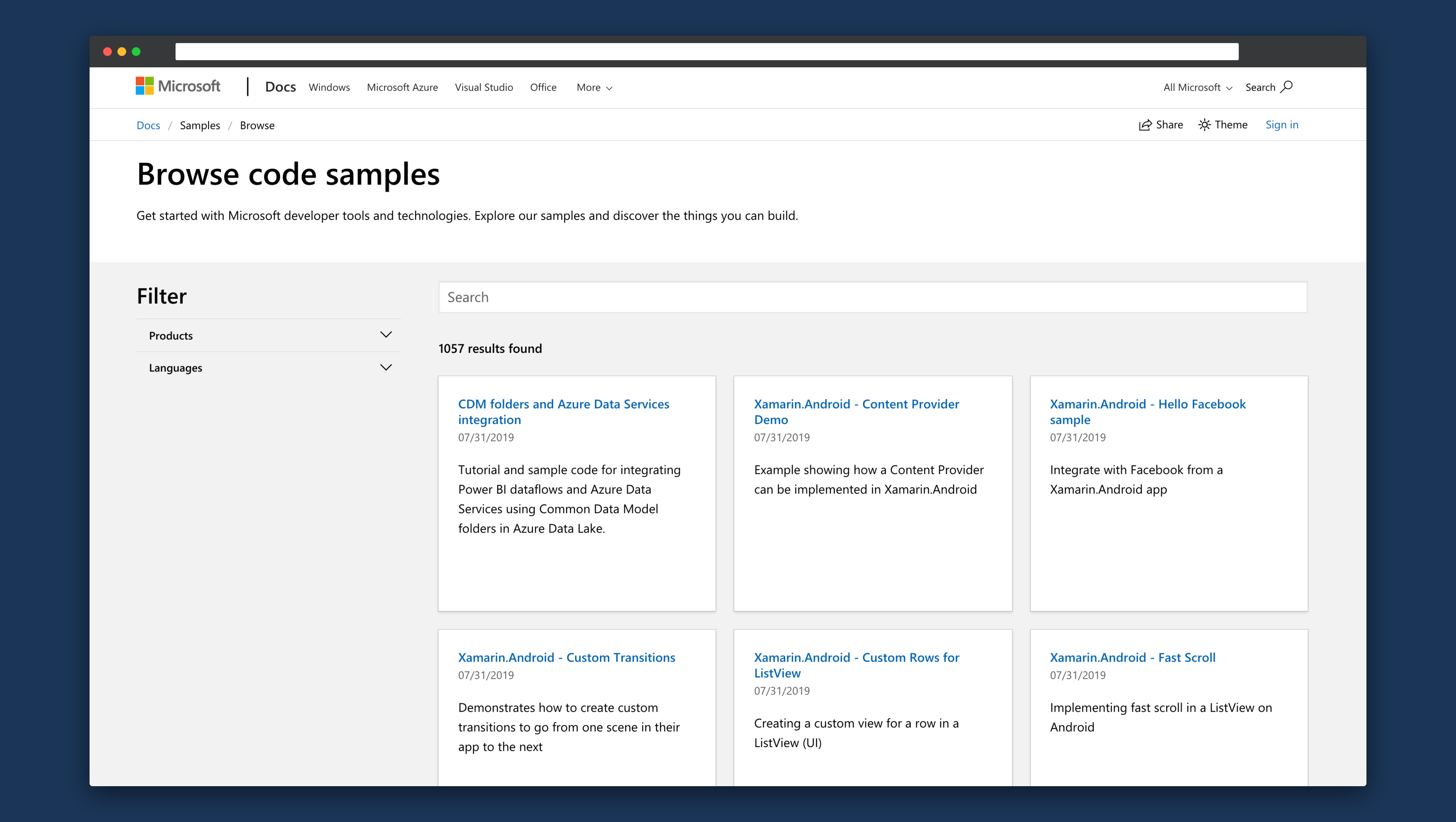
Looking back #
When we first started the project, we wanted to come up with a workflow through which we can index samples from various locations within GitHub, giving sample writers full control over the content and the process. The location of samples was decided to be GitHub for fairly obvious reasons - that’s where teams were already working on most of their examples and production code (such as VS Code and TypeScript). We did not want to re-invent the wheel - there is no reason to create a siloed experience, where someone uploads the code and then maintains it as if it’s static content - an approach like this would add a lot of maintenance overhead and would not foster collaboration and work in the open.
As mentioned earlier, a large corpus of sample code was already hosted within GitHub - teams gravitated to it naturally, being laser-focused on community and standard contribution patterns. For example, we maintain the Azure-Samples GitHub organization, dedicated entirely to code samples. The Azure Code Samples gallery is powered by content coming from that organization alone, and developers would count on content hosted there daily. Every public repository would map to one sample, that would be discoverable to anyone. This experience, however, was only available for Azure samples - there are plenty of teams within Microsoft that would not be “eligible” to be included in this experience.
As the number of code samples we hosted on GitHub grew, we also quickly ran into an interesting challenge - often times, teams would create more than one code sample in a single repository. Someone who wrote ten or fifteen Python samples for Azure Cognitive Services had no reason to create ten different repositories - that would both clutter the organization, and create mental overhead for customers who want to find relevant code. The solution was to group the samples in a single repository. The container repository would then grow more, but the gallery would still list one sample for it - because there is a one-to-one mapping between repositories and gallery entries. We needed to find a better way to scale and provide a bit more control over what samples needed to be shown.
With some basics lined up, we proceeded to write extensive specifications with detailed plans for the engineering teams to build.
First steps #
The goal was clear - we want to index samples not on a per-repository basis, but rather based on a more declarative approach. If a repository housed ten different samples, we wanted the maintainer of the repository to tell us where those samples are, so that we can treat them each as an individual entry in our index. A possibility would be using an automated approach, by which we’d establish some heuristics for what defines a sample, and then scan for folders that would match that pattern. This idea fell apart because of just how much variability there is in code configuration and organization - we’d have to constantly refine the indexer just to keep up with various formats and types of code developers would write. The second idea we thought to be useful was the creation of a “sample manifest” - a YAML file that would contain metadata related to the sample. Things like the list of programming languages the code sample covers, a list of products it applies to, a slug to be used to construct its URL and other values that might prove useful. A similar model is already used on docs.microsoft.com for structured content (see example for an auto-generated Python API documentation page).
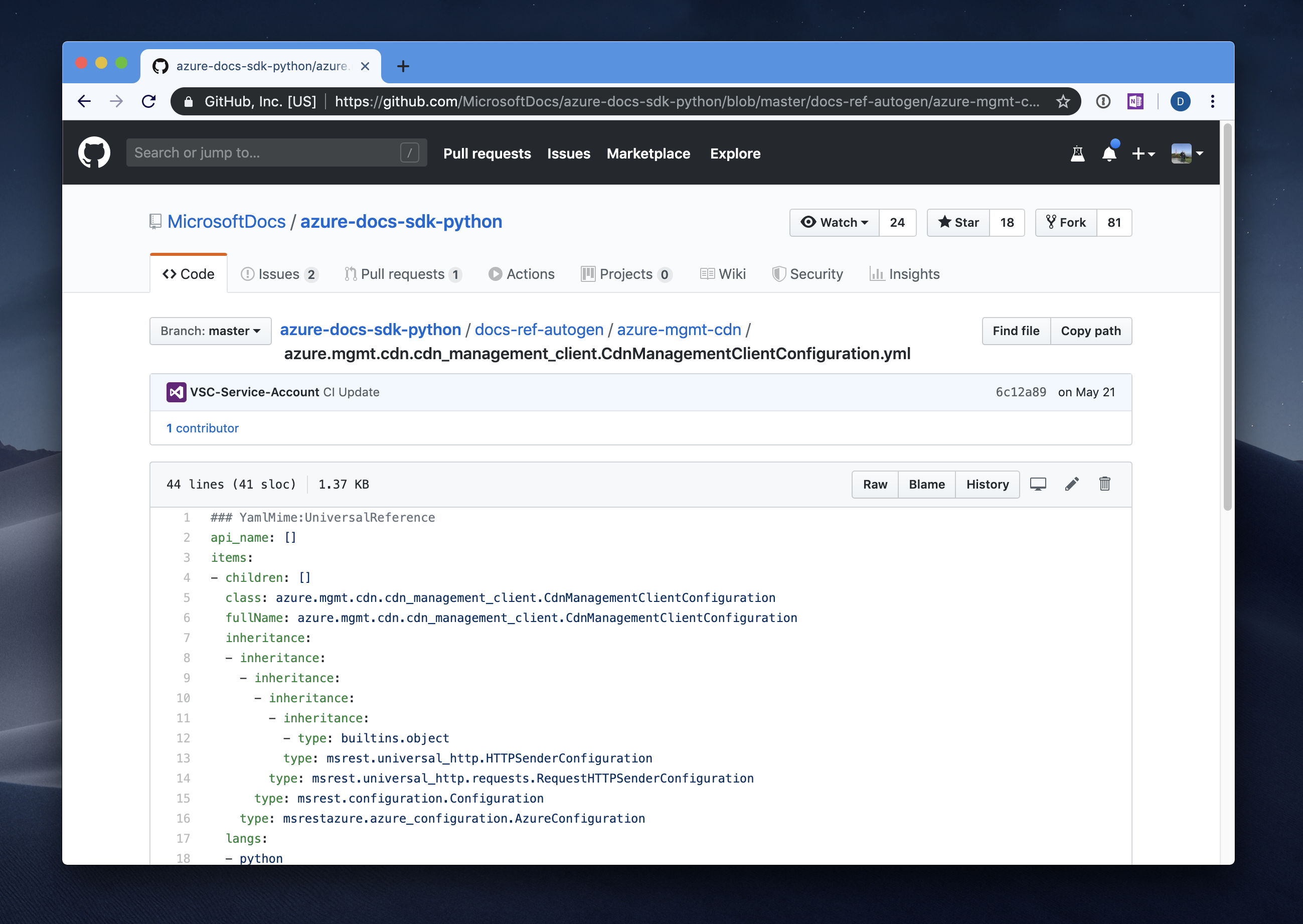
We would just adapt it to samples with a custom schema. If a sample maintainer wanted to declare ten different samples in a single repository, they would need to create ten different YAML manifest files in the folders where the samples are located. Each manifest would look something like:
### YamlMime:Sample
languages:
- csharp
- vbnet
- azurecli
products:
- azure
- azure-app-service
summary: "My amazing sample does all the amazing things!"
urlFragment: my-amazing-sample
This way, the sample maintainer has full control over what they want to “declare” as a sample - whatever has a manifest in it matters to the indexer.
To track changes, we built an indexing API, that was connected to the repository through a standard GitHub webhook. Whenever a change would happen, we would kick off the sample processing workflow, in which we’d try and detect whether code changed in an area that is associated with a manifest (i.e. there is a manifest YAML in the sample folder). If that was the case, we’d queue the processing message, and once its turn came, it would be analyzed, the sample index would be updated, and the sample manifest along with the README.md file for the code sample would be copied over to the publishing repository (which acts as any other docs.microsoft.com repository for content) from which we’d generate individual site pages.
The service diagram below explains at a high level what this would look like:
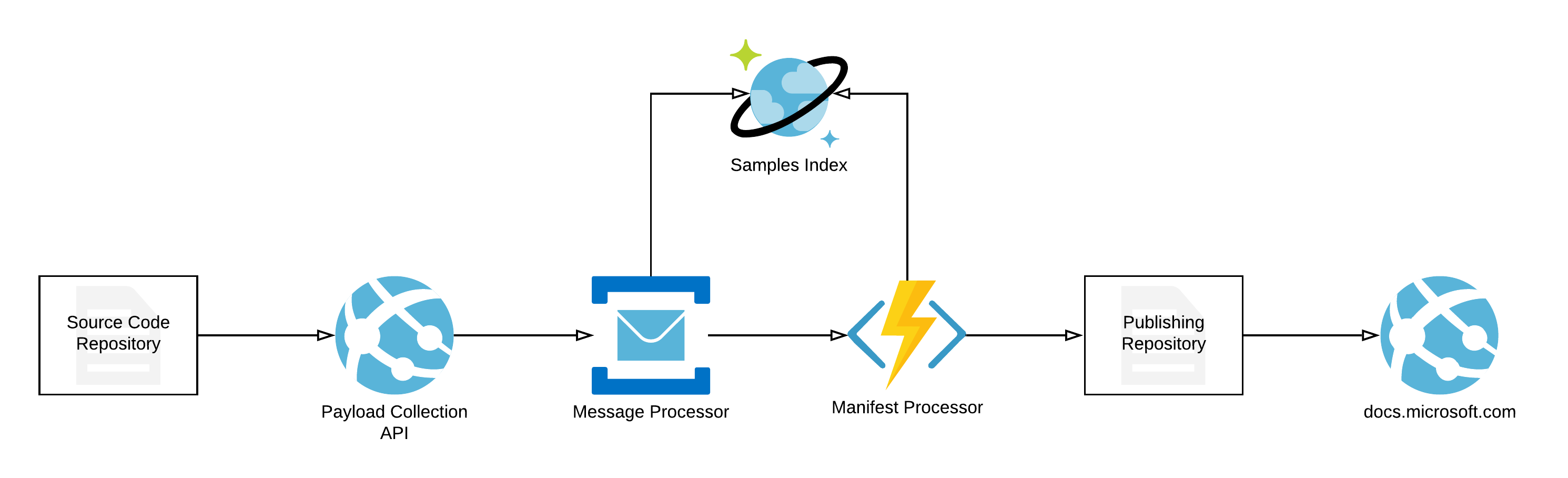
During the validation stages, the service checks for several criteria:
- Validity of the YAML front-matter. In some cases, there could be issues with the formatting or the structure of the YAML. For example, someone forgot to add the closing
---separator. - Validity of specified
productsandlanguagesvalues. We use these to identify facets by which we need to filter samples on the samples browser homepage. - Conformance of the YAML to schema expectations. For example, if someone uses an array in a field where a string is expected.
If the sample content was valid, we would kick off a job that would build the archive (ZIP) for the specific sample and insert it in the sample repository as a release. We once again decided not to re-invent the approach to code distribution - a sample release is accessible both from GitHub and from our own online experience, so there was no need to implement a detached storage management workflow. The value-add here is that with this capability, customers can download just the sample they need instead of potentially cloning a large repository.
The first iteration of the service was built relatively early on, and we started testing it on a select number of repositories. The YAML manifests were OK in terms of doing what they were supposed to do, but we also realized that there was a huge usability roadblock. When sample maintainers would update the sample in their repository, they would focus on things that are important to the specific code - the README.md and the code itself. The manifest was forgotten about because updating it too is not a natural habit that any developer or content engineer has. It’s just not a priority to update sample metadata when you worry about delivering production code that the sample is supporting. So we went back to the drawing board - there needed to be a different approach to how we track samples. The goal of making the overall process as frictionless and natural as possible remained alive.
Improving the experience #
As we were iterating on the service and ingestion scenarios, an approach was proposed that would be something that we already use on docs.microsoft.com - YAML front-matter. Additionally, Azure samples were leveraging user-facing metadata in a similar manner within the existing code gallery - introducing some modifications to the requirements would be less painful than using an entire new detached manifest. And it renders nicely on GitHub.
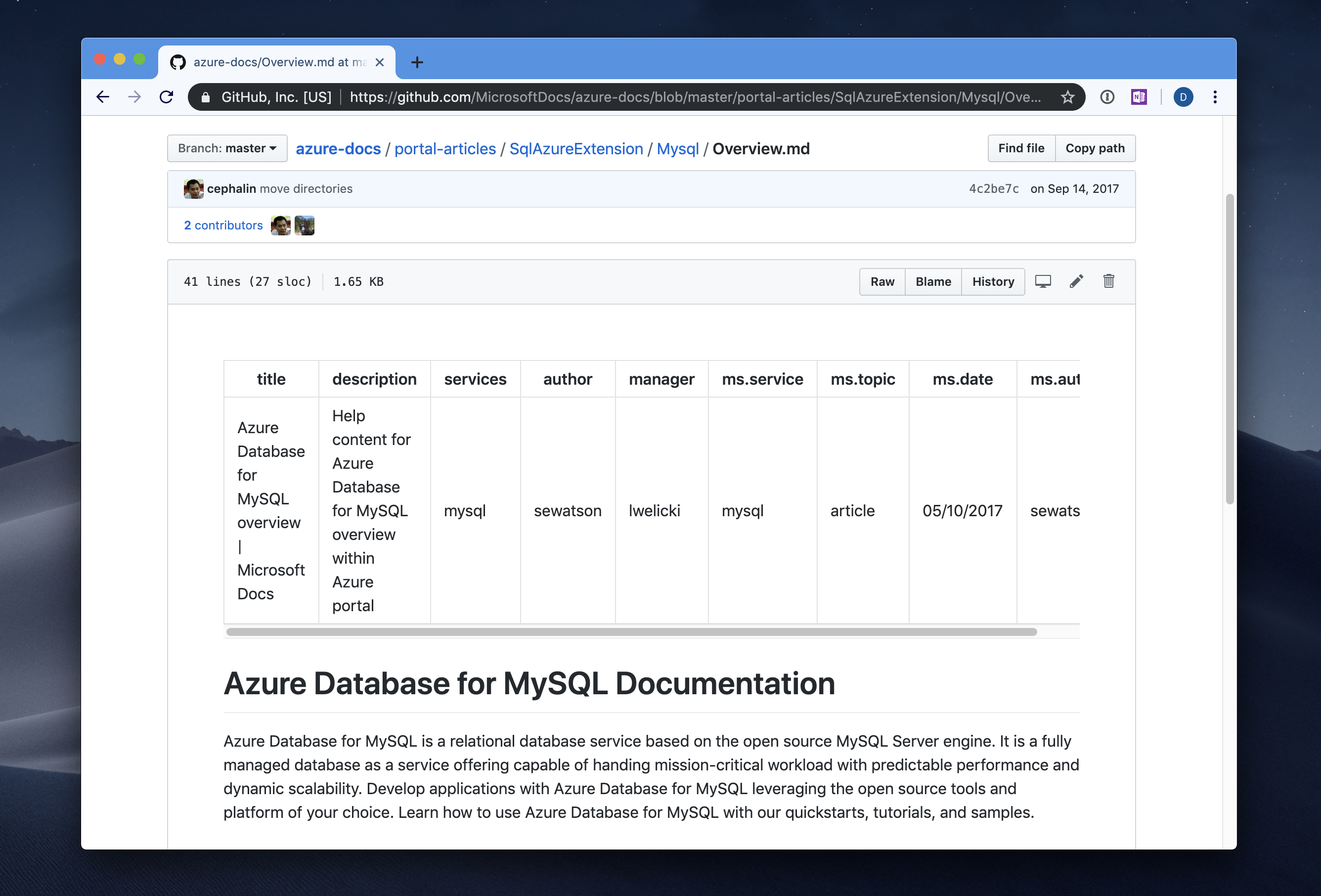
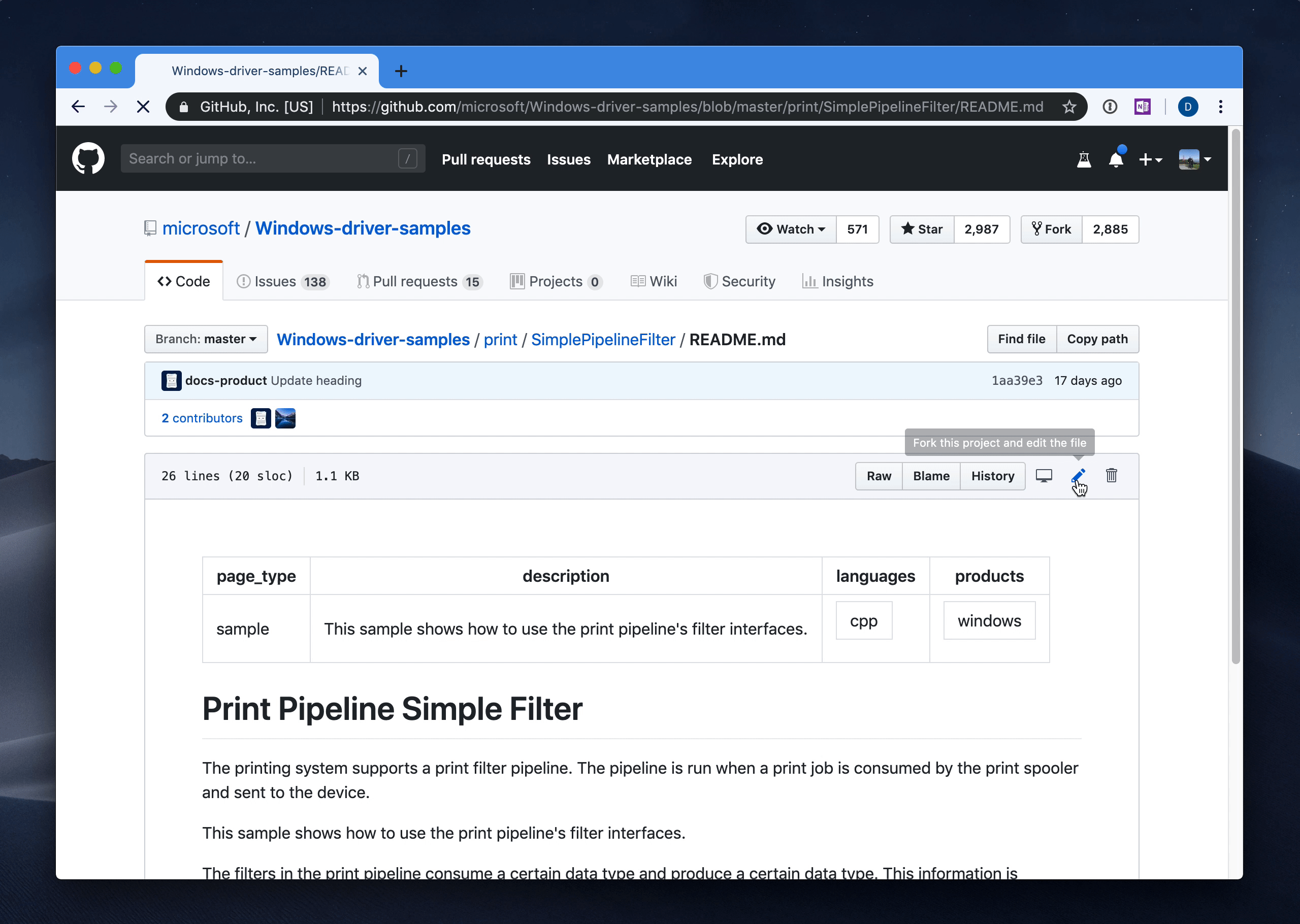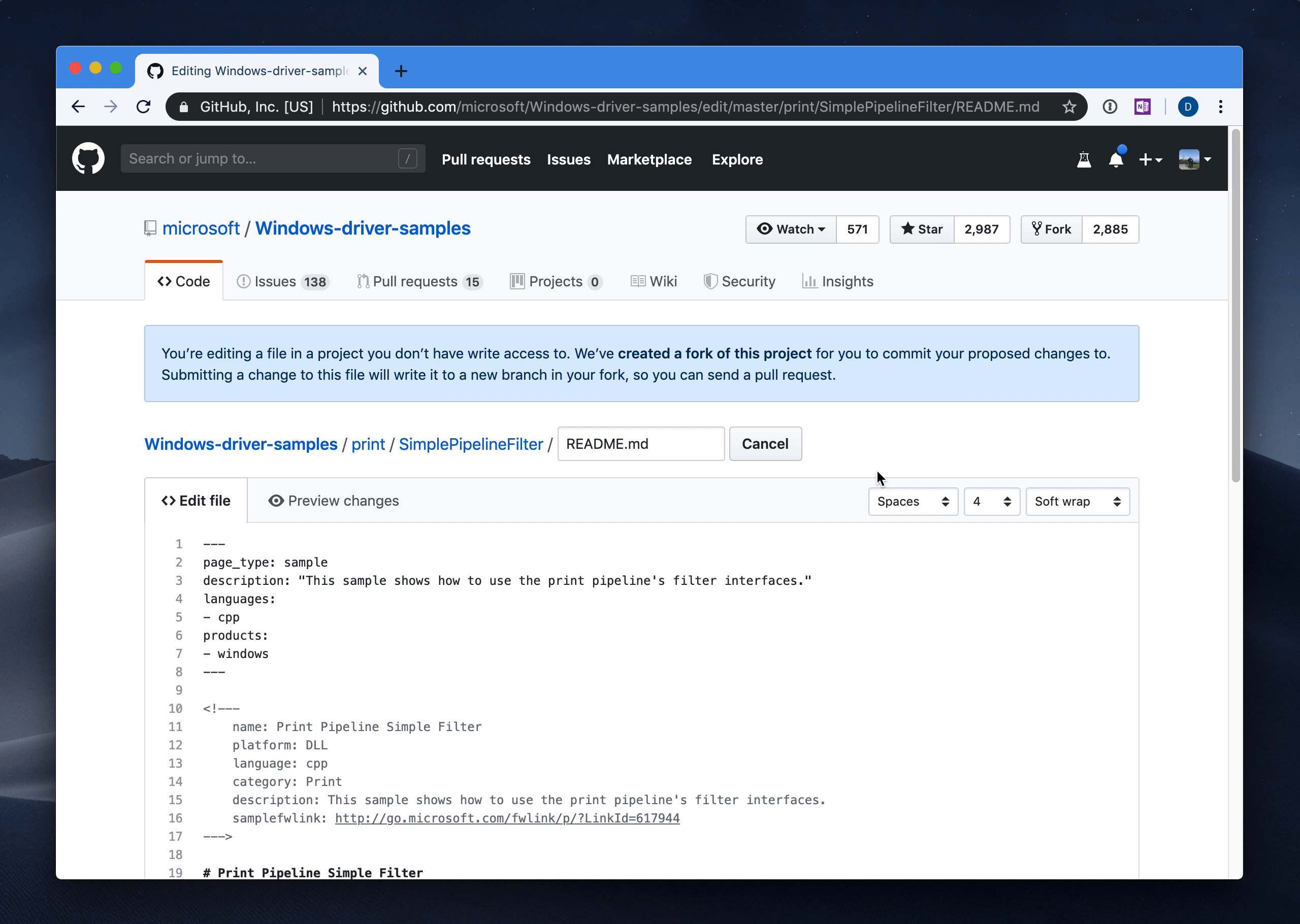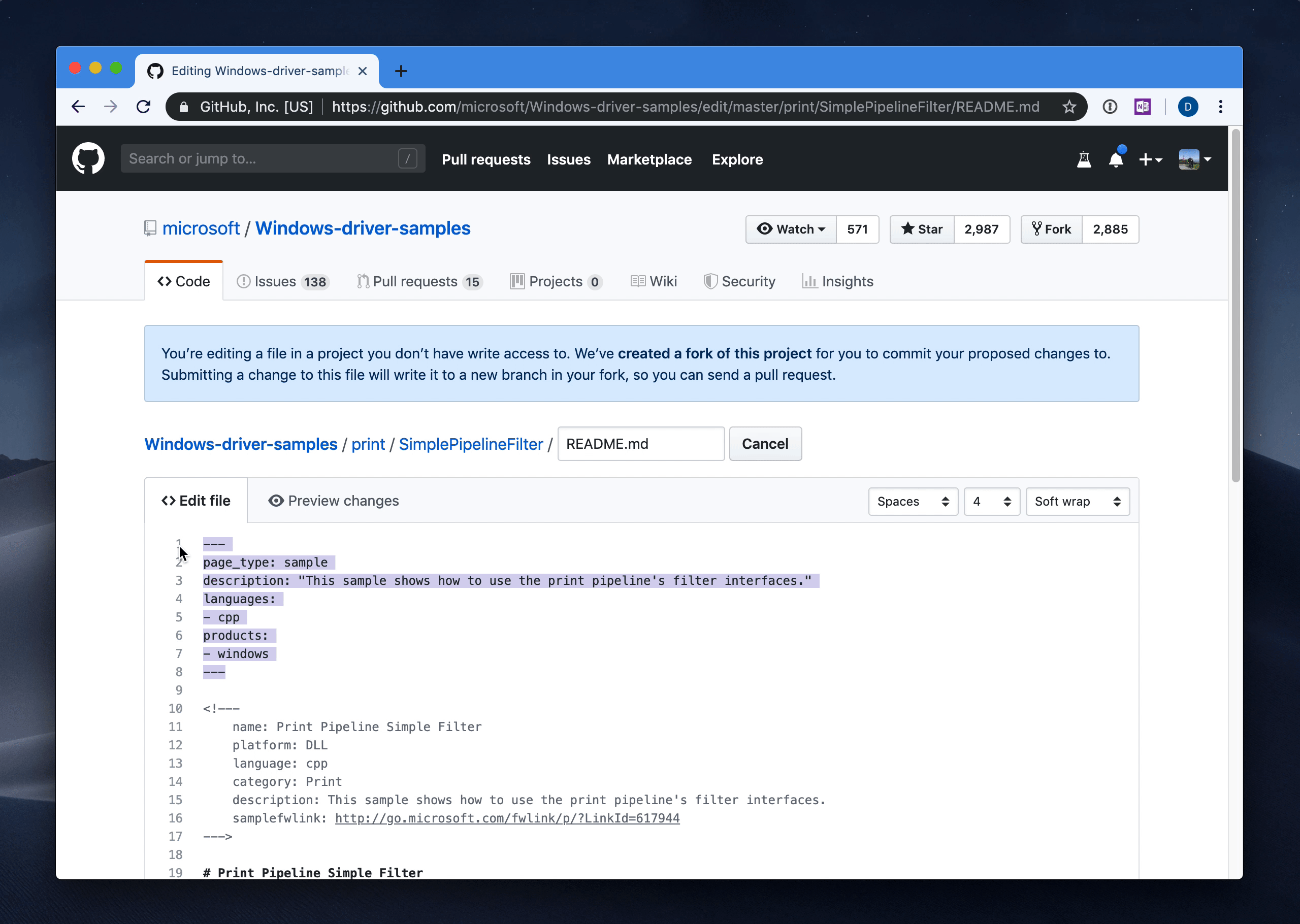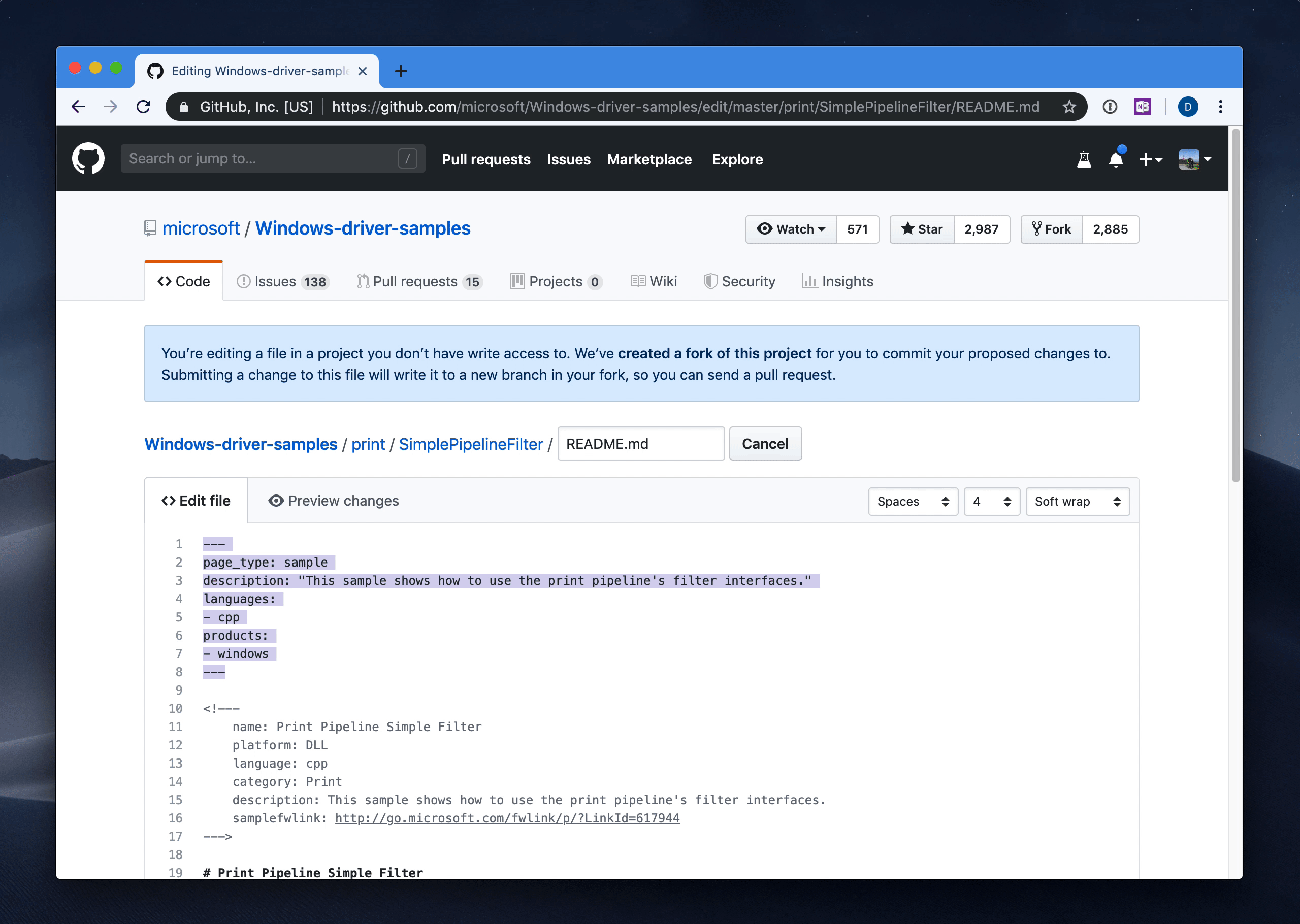
This was the approach we wanted to adopt moving forward. Instead of having a vanilla YAML manifest, the README.md will be structured with a bit of added content, while still serving the purpose of being the guideline document for the sample consumer:
---
page_type: sample
summary: "This sample shows how to use the print pipeline's filter interfaces."
languages:
- cpp
products:
- windows
author: "den"
---
# Print Pipeline Simple Filter
The printing system supports a print filter pipeline. The pipeline is run when a print job is consumed by the print spooler and sent to the device.
The front-matter would tell us that something is a sample vs. not. Every README.md in the repository that has a page_type: sample metadata value would be queued for processing and indexing. Every other README.md is ignored by default. This means that within a single repository, many samples can be declared and live side-by-side with content that doesn’t necessarily need to be rendered on docs.microsoft.com.
YAML front-matter was a favorable choice from several angles:
- It’s easy to integrate in existing
README.mdfiles. No need to maintain any separate artifacts that a sample maintainer has to update whenever they update the sample - just take a glance at the metadata whenever they modify theREADME.mdfile. - YAML front-matter is natively supported by GitHub and renders as a clean table rather than a blurb of unformatted YAML.
- Following the same patterns we already guided content engineers on.
- The structured format is easy to visually parse and understand in the context of the
README.mdfile being worked on. - Easy to automate and validate the same way we do that with docs.microsoft.com content.
We ended up with a relatively simple model that we applied to some samples as a pilot.
After receiving more positive feedback from content and sample engineers, we moved forward with the full implementation. In addition to basic metadata values within the front-matter, we also identified several opportunities to add even more flexibility to sample authors. For one, we realized that when we generate ZIP packages for each individual sample, there are often times dependencies within the repository that the sample relies on - that gave us the idea of implementing extendedZipContent. This is a metadata value that allows specifying custom content from within the repository that needs to be included along with the core sample.
Similarly, we have a large number of samples that have Azure Resource Manager templates associated with them for each deployment. Given that the sample author already provides that artifact, we thought we’d make it easy to make sure that there is a one-click deployment option available.
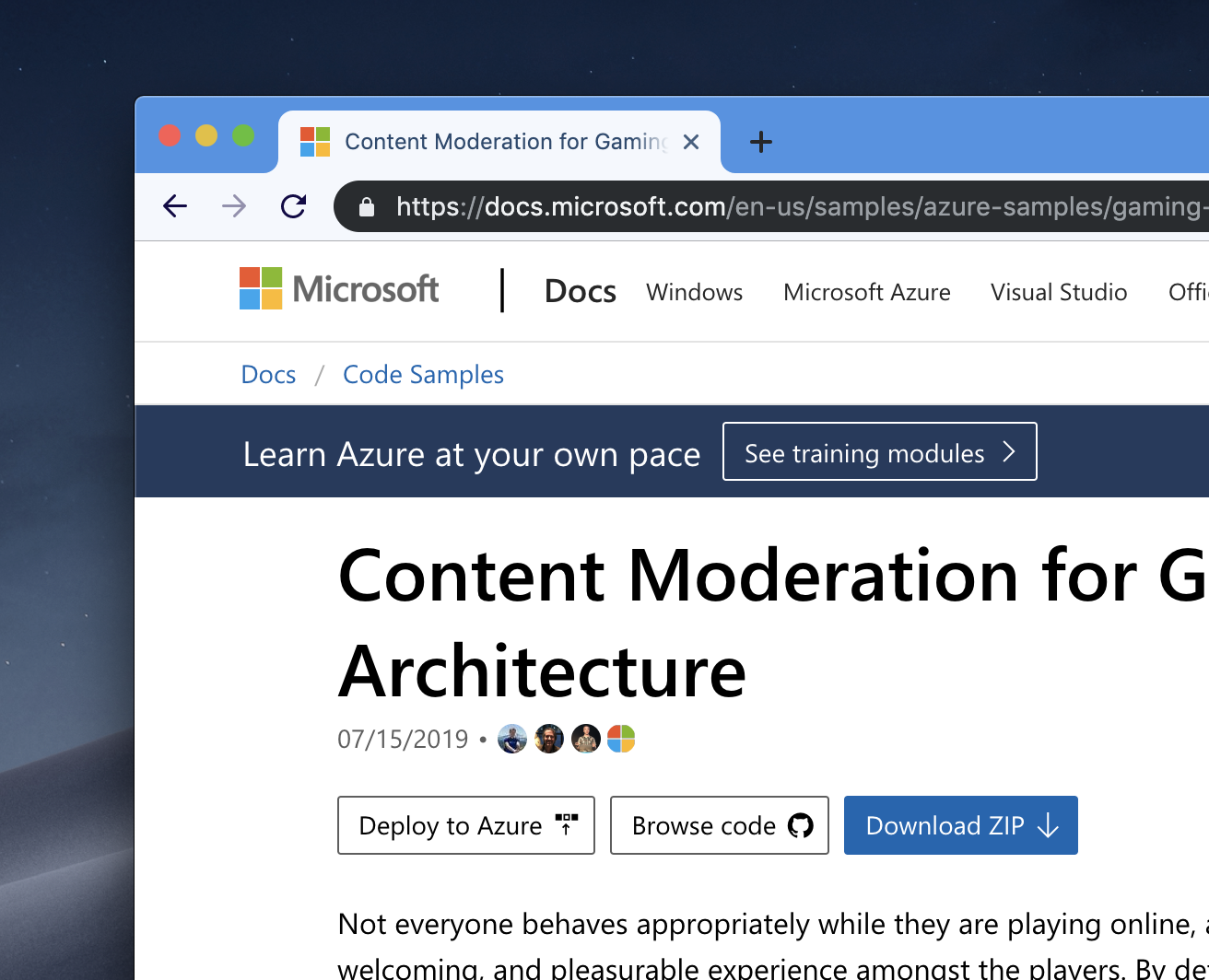
The “Deploy to Azure” button is powered by azureDeploy metadata - the sample maintainer can provide an absolute URL to the template, and we’ll automatically create a deployment link for it on the frontend.
Pretty much anything about the sample being shown on the samples browser home page can be controlled through the YAML front-matter - and we love that simplicity.
Published pages #
When samples are processed, we are generating a structured representation of the code sample page (such as the one for the MSAL Node) based on a schema that is understood by DocFX, our underlying content build platform. The generated files are post-processed YAML content that integrates front-matter metadata and README.md Markdown in one, which is later dropped in a publishing repository.
The need for a schema is grounded in the our practice of ensuring that every page that we render is following a specific strict template - this gives us the ability to render things consistently. With the Schema-based Document Processor engine that our team built, we can do just that. A sample page in this context has a schema, and if an incoming file does not follow expected page constraints, the build will fail. Because we are already using docs-related infrastructure, the schema creation and validation process was relatively straightforward.
Additionally, when we publish new sample pages, we automatically copy over all media that is referenced in the README.md file, so that we still have images available, even though the new content is now sourced from a separate repository.
You might be wondering - with all the hassle that is copying content over, and then maintaining two copies, why not just ingest sample code from the sample repository itself, instead of transporting the README.md and all its media into another location? Pure and simple, we wanted to keep sample repositories clean of docs-related configuration files, and maintain a high-performance system. If we would have to provision every sample code repository with publishing artifacts, that would introduce a number of extra configuration files that need to be maintained by someone experienced in our publishing system. If those are accidentally removed or modified, this would break the publishing for that sample. Additionally, all code samples that we publish on docs.microsoft.com/samples are released under the same base path in the URL - /samples. If that base path starts being shared between ten, one hundred or even one thousand repositories, this would impact the hosting service as for every call we’d need to perform a lookup to understand where a sample is coming from.
Putting post-processed content in a publishing repository made a lot of logistical sense.
Automating releases #
As some of you already know, docs.microsoft.com has two environments - production, that is normally reliant on content from various repositories that is made available in live branches, and review with content pulled from the various repositories from branches that are not live. When sample code is processed and publish-ready pages are generated, those are automatically dropped into our staging environment. Samples are updated relatively frequently, and when you have more than one thousand of them, new files appear in the publishing repository every hour. We wanted to eliminate the human factor from the publishing process, and because all samples are already public (we do not index anything from private repositories), we want to make them public as soon as possible.
That’s where pull and probot-auto-merge come to the rescue. First, pull regularly creates pull requests to sync master and live branches. Subsequently, probot-auto-merge ensures that pull requests that have a certain label and with all builds passing are merged. When that happens, the docs publishing system kicks off a new content build, and public pages are generated on docs.microsoft.com/samples!
Stack #
Here is a brief outline of what we use for our infrastructure:
- Azure CosmosDB is used to maintain the “source of truth” index of code samples that need to be added and removed from the publishing repository.
- Azure Event Hubs is used to queue and process messages that we receive from various webhooks across the sample repository set.
- Azure Functions are used to process sample manifests from the queue.
- Azure App Service is used to host the various connecting APIs that monitor and index the samples.
- Azure Monitor is used for indexing/ingestion diagnostics and telemetry.
- Azure Pipelines is used for building and deploying the samples infrastructure, as well as for generating all sample-related artifacts.
- DocFX is used to generate pages on the docs.microsoft.com site.
There are more tools and components under the hood, of course - the above are just the major pieces that make things run. There is a lot of integration plumbing that was built to inter-connect the services and ensure that we can catch potential issues at every step of the indexing and publishing process.
Conclusion #
To deliver this experience, it took the effort of tens of individuals across teams and organizations within Microsoft. Design, engineering, product management, content and marketing were involved in making our vision of a single samples browser a reality. There are too many people to mention in a single post, so I’d like to call out a few that have Twitter accounts:
- Jeff Sandquist (product management)
- Erin Rifkin (product management)
- Dan Fernandez (product management)
- Mikhail Melnikov (engineering)
- Anton Sokolovskiy (engineering)
- Mike Sampson (engineering)
- Adam Kinney (engineering)
- Will Bjorn (engineering)
- Duncan Mackenzie (engineering)
- Kurtis Beavers (design)
- Craig Dunn (product management)
- Sarah Barrett (information architecture)
- Jeff Wilcox (engineering)
- April Speight (product management)
And many, many others (if I missed you, DM me and I will add your name - I likely forgot your Twitter alias). All the thanks should go to the individuals above and the many other engineers and partners that made this happen. Thank you!