How I Built A Custom Halo Infinite Data API With Netlify
Comes to no surprise if you read my blog or follow me on Twitter (or maybe you’re even following @OpenSpartan if you’re that into niche content) that the Halo Infinite API has been somewhat of a focus domain for me for the past year. It single-handedly took over most of my free engineering time because it’s that interesting to me as a frequent Halo player. And yes, I can already hear you going “Ah for Pete’s sake, another Halo-related blog post?” Yes, dear reader, another Halo-related blog post.
A part about the Halo Infinite API that is particularly interesting has been the one where recent and all-time play data is made available for game assets such as game variants and maps. 343 Industries does not necessarily offer any out-of-the-box insights on map or game mode performance, but it so happens that the exact (or, allegedly exact) data is embedded within the API responses that are provided by the undocumented Halo Infinite API. These numbers are embedded in API responses that deal with projects and game build manifests. The values in those API calls, unfortunately, are not really showing any historical trends, which makes it extremely hard to see movement as to how happenings like in-game events influence the play volume. If I make an API call, I can see the point-in-time volume, but that’s where the fun ends. I don’t know when fluctuations occur or when changes are the highest.
To mitigate this issue, a few months back I decided to use my own little SDK that I wrote for the Halo API to create another tool - StatLink that would query the API endpoints regularly through scheduled GitHub Actions and commit the play data into a TSV file in a GitHub repository. Every game asset would have its own directory structure, of course, where it would contain the data file, some metadata, and any associated hero and thumbnail images. Easy enough, right?
Next step for me was making sure that I can use that data through a web interface (that is coming very soon). But how do I do that with just some random TSV files that are stored in GitHub? Several options come to mind:
- I could query the files independently. That means that for every TSV file with data that I have in the repository I need to somehow keep a reference in my web application configuration. When it comes to new files being placed in the repository (let’s say a new map, like The Pit gets released) I need to update the web app configuration to account for it.
- I could expose the files through an API. This implementation would enable me to dynamically pick up the list of produced files and use the data for them as it becomes available with zero changes to the web application that will be consuming them.
I chose the latter because I like APIs and I don’t like routine, boring, and repetitive work. But how do I build this API with the absolute minimal amount of friction, since I don’t want to re-implement all the complexity of GitHub API interactions for this very specific task?
The easiest way to do that, at least in my mind, was using Netlify Functions and Netlify Graph. The former would allow me to have an API without having to host a server somewhere, and the latter enables me to talk to GitHub without using too many dependencies and handling authentication manually. Because I am already relying on account impersonation (I don’t need to ask the user to authenticate), I can authenticate once through Netlify and then have the backend infrastructure handle all the token magic for me.
The serverless function here would be doing the heavy lifting, while Netlify Graph would be the “proxy” that could get me what I need from GitHub. In very plain terms, the flow would look like this:
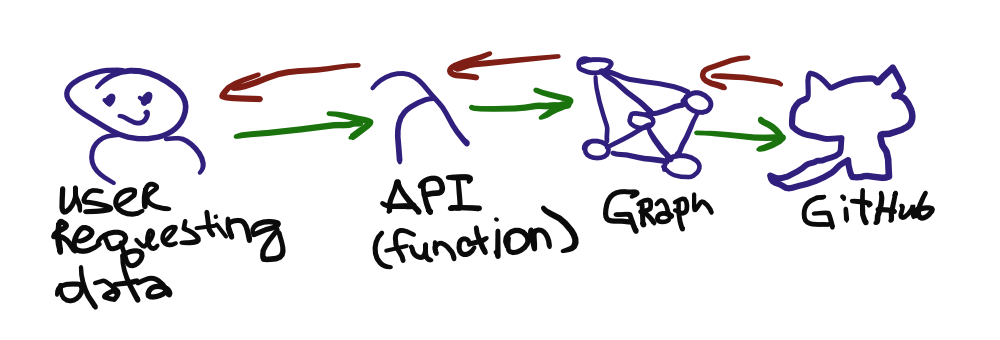
This highly-convoluted scientific drawing represents a fairly simple process:
- User requests the data from an API endpoint.
- The endpoint actually directs the request to a serverless function running on Netlify.
- The function then calls Netlify Graph through a pre-defined service token that it manages internally, that is entirely opaque to everyone involved in the process.
- Netlify Graph talks to GitHub on behalf of the user with the up-to-date OAuth credentials (which it maintains), requesting the information about the existing files in a pre-defined repository (in this case
openspartan/openspartan-data-snapshots). - The information is the returned to Graph, which passes is back to the serverless function.
- With the breakdown of available entities (engine game variants, maps, or game variants), the function then goes and downloads the raw metadata and TSV files (because the URLs are highly predicable based on asset IDs).
- The data is re-shaped into a JSON blob and returned to the user.
There are two angles to the API, though. One is that I want to first get the list of available assets which means that I need to get the raw data from Netlify Graph about the repository contents. This is where getting GitHub data in the most simple manner is extremely useful. Second is that once I actually have the list of available assets I want to be able to retrieve a specific asset by its asset ID and version ID. The latter is easier once you have the list because I can just query the https://raw.githubusercontent.com/ endpoints on GitHub to get public contents without being constrained by API limits.
To address generic asset lists, I segmented my API into three core endpoints - /maps, /gamevariants, and /enginegamevariants respectively for each asset type. Let’s take a look at the contents for the /enginegamevariants function (enginegamevariants.ts) to see what exactly is happening:
import { Handler } from "@netlify/functions";
import process from 'process';
import fetch from "node-fetch";
import { GameEntity } from './models/GameEntity'
import { APIError } from './models/APIError'
export const handler: Handler = async (event, context) => {
const nff = require('@netlify/functions');
const secrets = await nff.getSecrets(event);
const accessToken = nff.getNetlifyGraphToken(event);
let data = new Array<GameEntity>();
await fetch('https://graph.netlify.com/graphql?app_id=ed4ae77f-d030-40bb-a8d1-26e1d5a3e640&show_metrics=false',
{
method: 'POST',
body: JSON.stringify({
query: `query GetMaps {
container: gitHub {
entityCollection: repository(name: "openspartan-data-snapshots", owner: "openspartan") {
entities: object(expression: "HEAD:data/engine_game_variants") {
... on GitHubTree {
entries {
id: name
versionContainer: object {
... on GitHubTree {
versions: entries {
id: name
}
}
}
}
}
}
}
}
}
`,
}),
headers: {
"Authorization": "Bearer " + accessToken.token
}
}
)
.then((r) => {
return r.json()
})
.then((jsonResponse) => {
for (let item of jsonResponse.data.container.entityCollection.entities.entries) {
let entity = new GameEntity();
entity.assetId = item.id;
entity.versionIds = new Array<string>();
for (let versionId of item.versionContainer.versions){
entity.versionIds.push(versionId.id)
}
data.push(entity);
}
})
if (data != undefined || data.length!= 0) {
return {
statusCode: 200,
body: JSON.stringify(data),
headers: {
'content-type': 'application/json',
},
}
} else {
let error = new APIError();
error.message = "Could not process the request at this time.";
error.code = 500;
return {
statusCode: error.code,
body: JSON.stringify(error),
headers: {
'content-type': 'application/json',
},
}
}
};
That’s quite a bit of reading, but there are only a few things that are crucial to what I am trying to accomplish. First, I am getting the secrets and the Netlify Graph token to be able to use the Graph-connected GitHub data.
const nff = require('@netlify/functions');
const secrets = await nff.getSecrets(event);
const accessToken = nff.getNetlifyGraphToken(event);
Next, I am fetching the data from Netlify Graph by POST-ing a query to the pre-defined Graph endpoint for my site:
await fetch('https://graph.netlify.com/graphql?app_id=ed4ae77f-d030-40bb-a8d1-26e1d5a3e640&show_metrics=false',
{
method: 'POST',
body: JSON.stringify({
query: `query GetMaps {
container: gitHub {
entityCollection: repository(name: "openspartan-data-snapshots", owner: "openspartan") {
entities: object(expression: "HEAD:data/engine_game_variants") {
... on GitHubTree {
entries {
id: name
versionContainer: object {
... on GitHubTree {
versions: entries {
id: name
}
}
}
}
}
}
}
}
}
`,
}),
headers: {
"Authorization": "Bearer " + accessToken.token
}
}
)
Notice that I am passing the Netlify Graph token as the bearer token for the request. I am not dealing with any GitHub-specific auth here. The endpoint, if you’re wondering, is available when you go to Netlify Graph settings for your site:
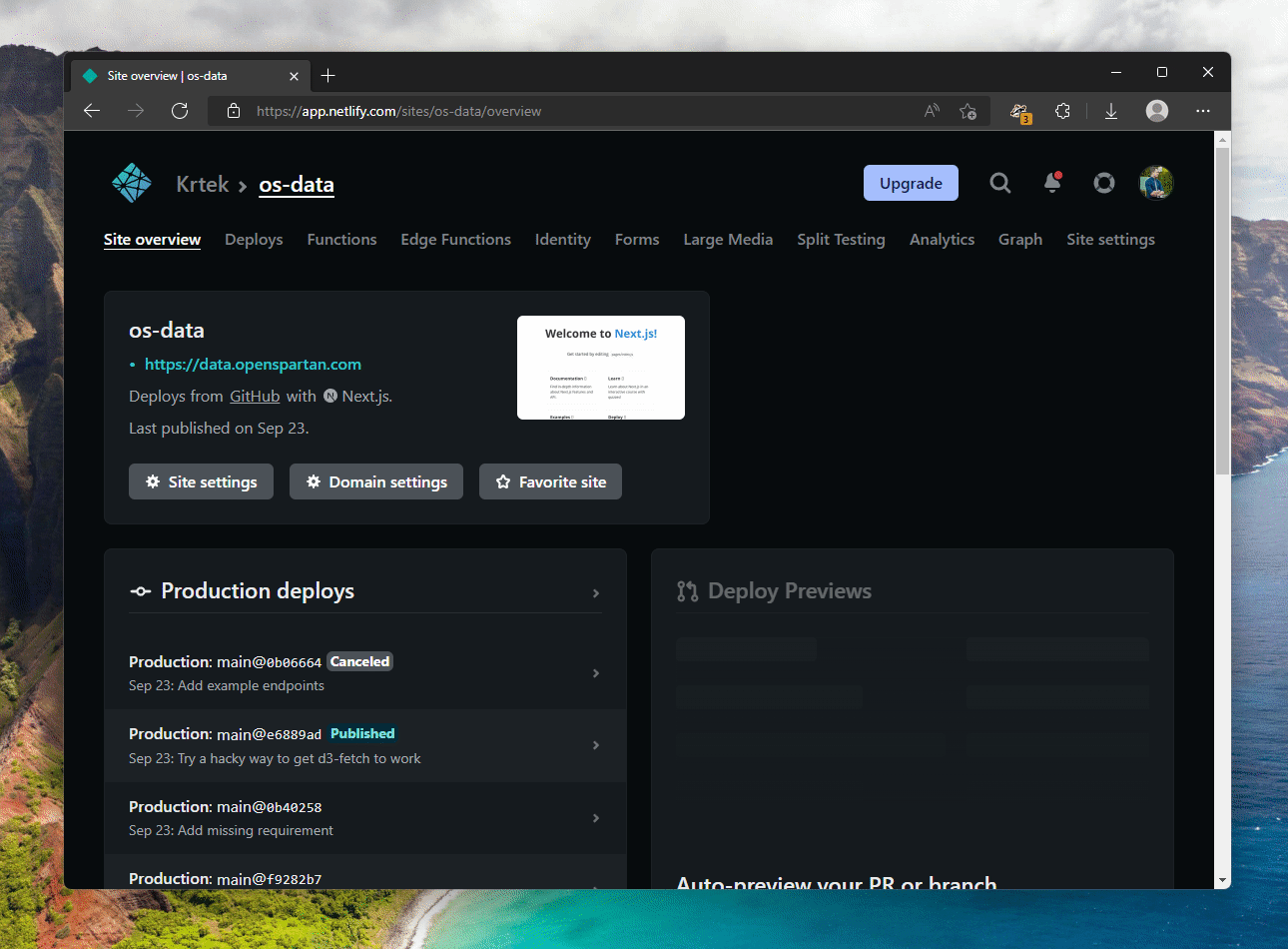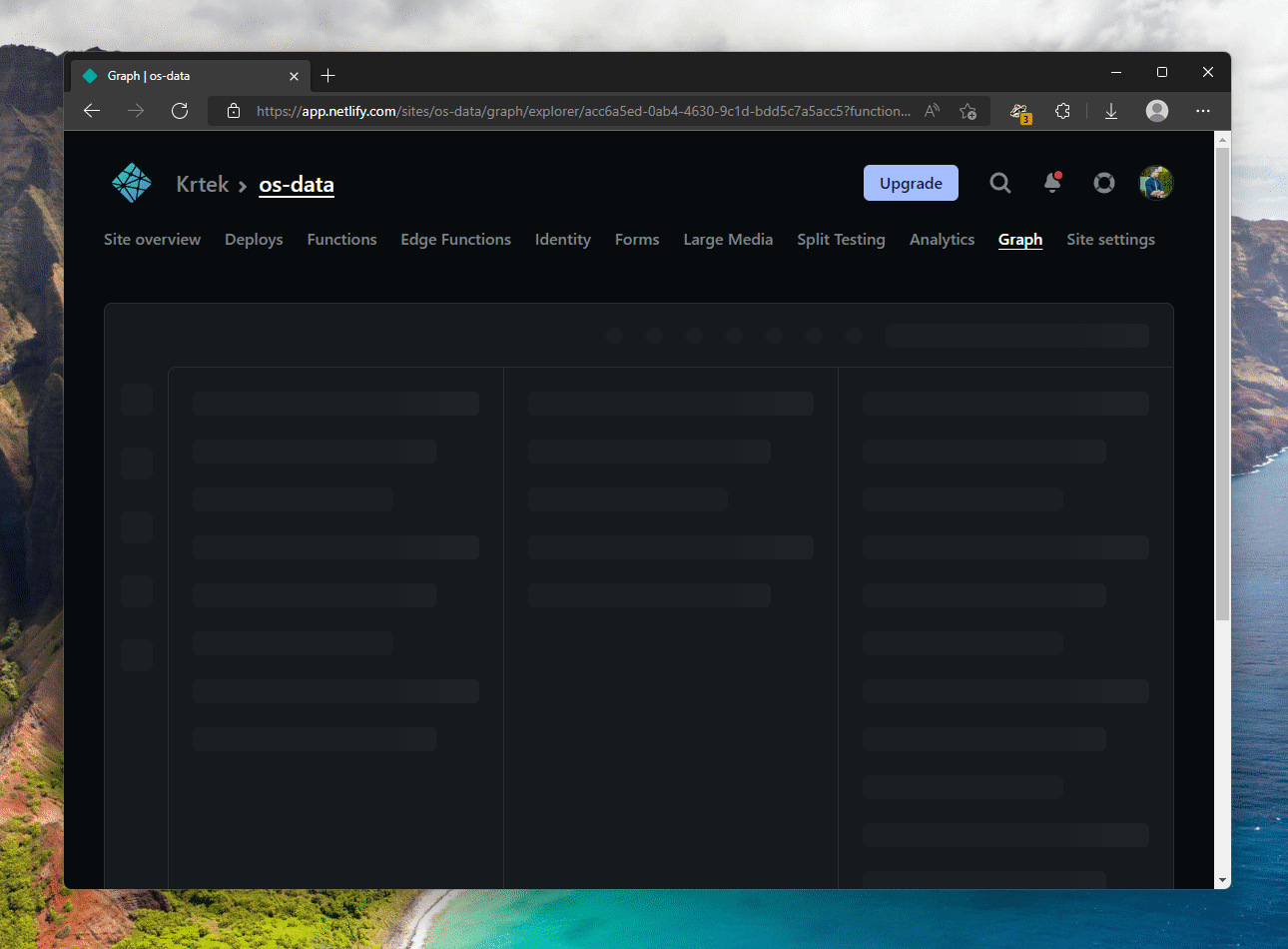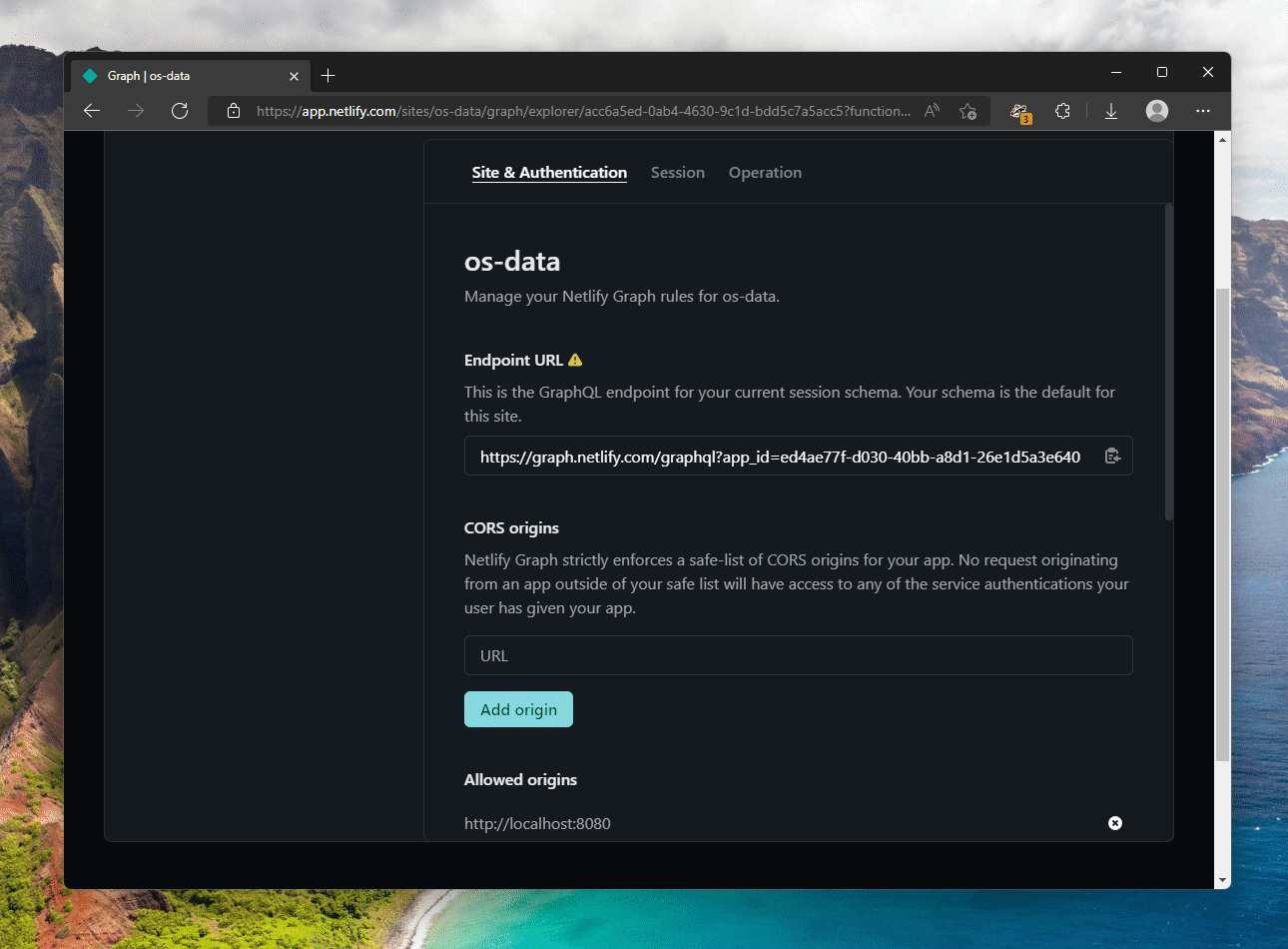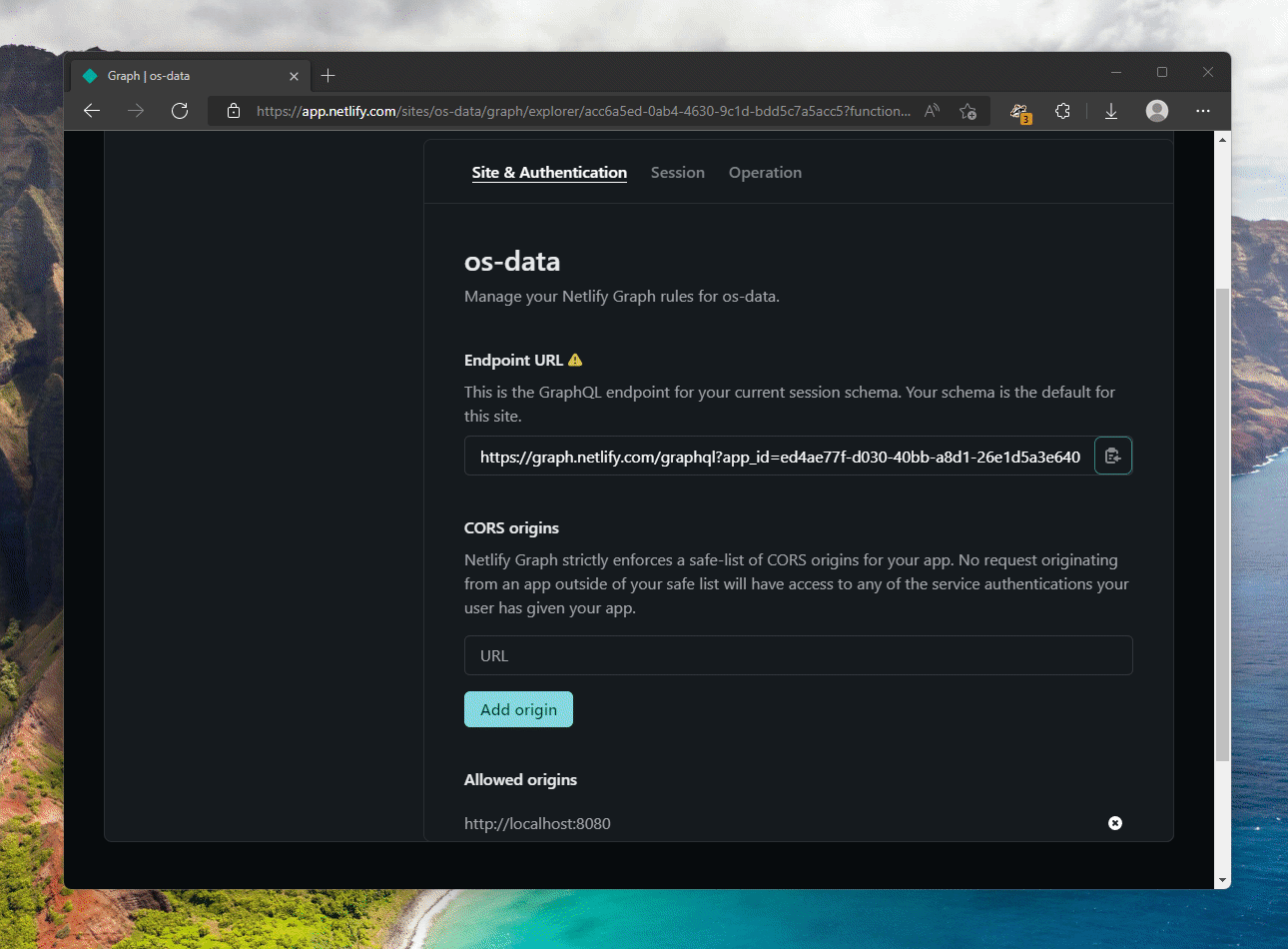
You can try queries out right then and there, along with connecting to any of the services that you want. In my case, I only needed GitHub, but it offered enough “headache removal” that it was worth talking through Netlify Graph (using the built-in API authentication feature) instead of using something like Octokit. But back to our code. Once the query is execute I am, admittedly in a very brute way, am transforming the data from the GraphQL-ized JSON into a more readable data model.
.then((r) => {
return r.json()
})
.then((jsonResponse) => {
for (let item of jsonResponse.data.container.entityCollection.entities.entries) {
let entity = new GameEntity();
entity.assetId = item.id;
entity.versionIds = new Array<string>();
for (let versionId of item.versionContainer.versions){
entity.versionIds.push(versionId.id)
}
data.push(entity);
}
})
Lastly, that data (or, array of game entities to be concrete) can be returned to the user in JSON form, cleaned up from all the unnecessary structures and with the possibility for error responses:
if (data != undefined || data.length!= 0) {
return {
statusCode: 200,
body: JSON.stringify(data),
headers: {
'content-type': 'application/json',
},
}
} else {
let error = new APIError();
error.message = "Could not process the request at this time.";
error.code = 500;
return {
statusCode: error.code,
body: JSON.stringify(error),
headers: {
'content-type': 'application/json',
},
}
}
That’s about it - that’s the function that acts as the API endpoint that retrieves available data.
I’ve connected a custom domain to my Netlify site (data.openspartan.com) and set up redirects in netlify.toml to make sure that I have a clean /api endpoint prefix instead of /.netlify/functions:
[[redirects]]
from = "/api/*"
to = "/.netlify/functions/:splat"
status = 200
This enables me to then have all the code above running through:
https://data.openspartan.com/api/enginegamevariants
I can now do the exact same implementation for other entities simply by substituting the target folder in my GitHub repository that contains the assets, so the expression in my GraphQL query above can become something like:
expression: "HEAD:data/maps"
And of course:
expression: "HEAD:data/game_variants"
Benefits of creating a clearly structured data collection, am I right? Here it is in action.
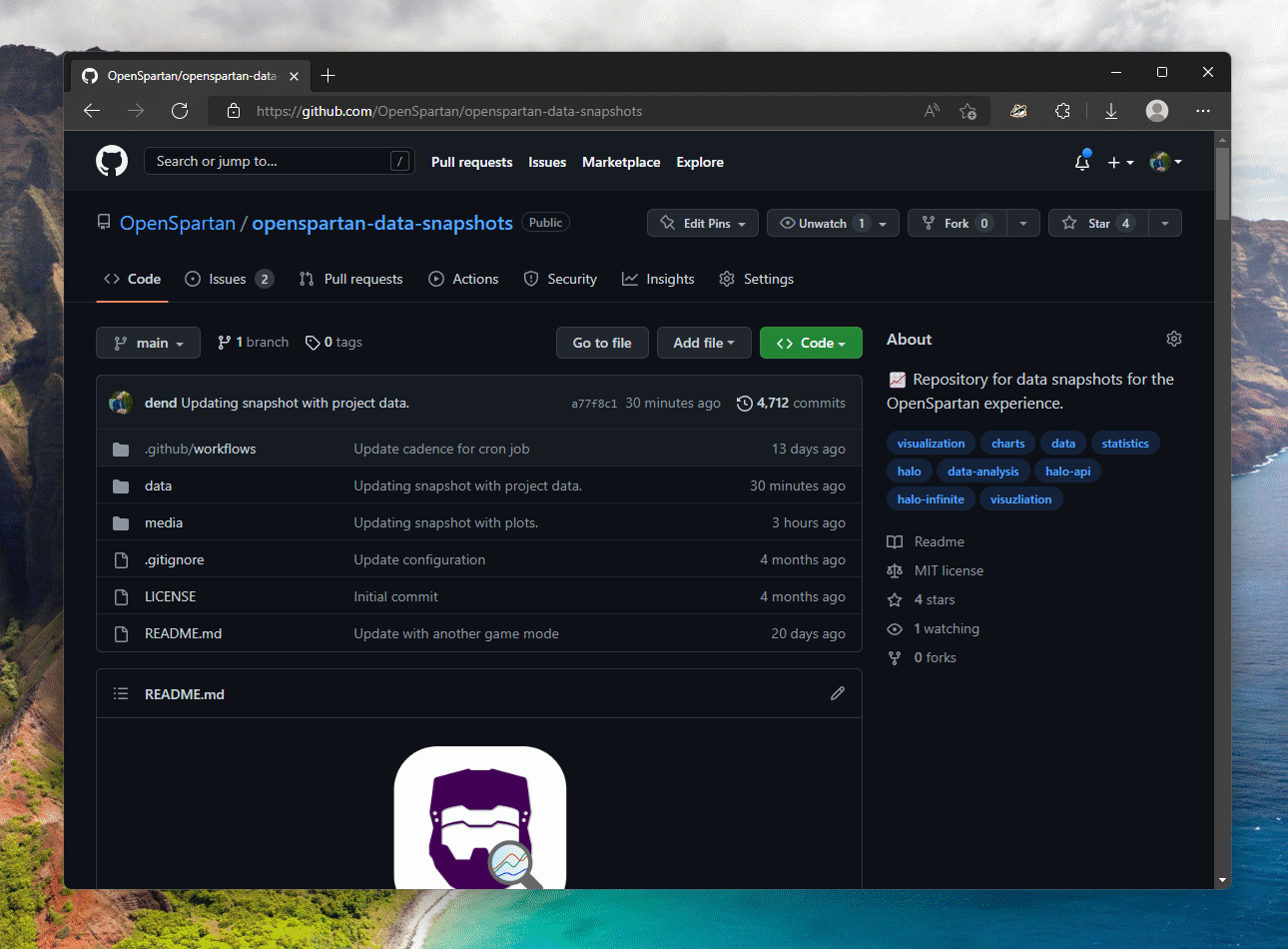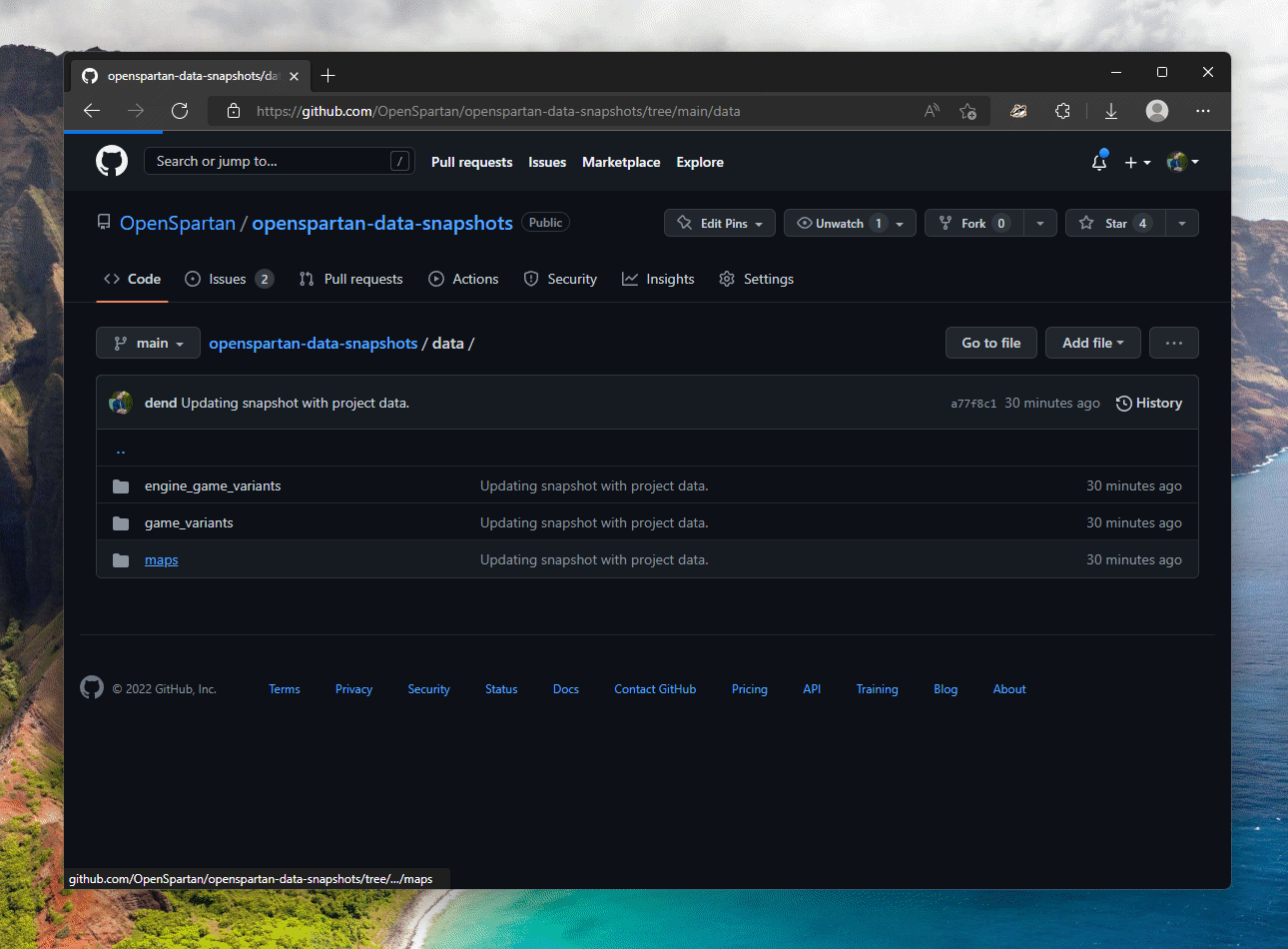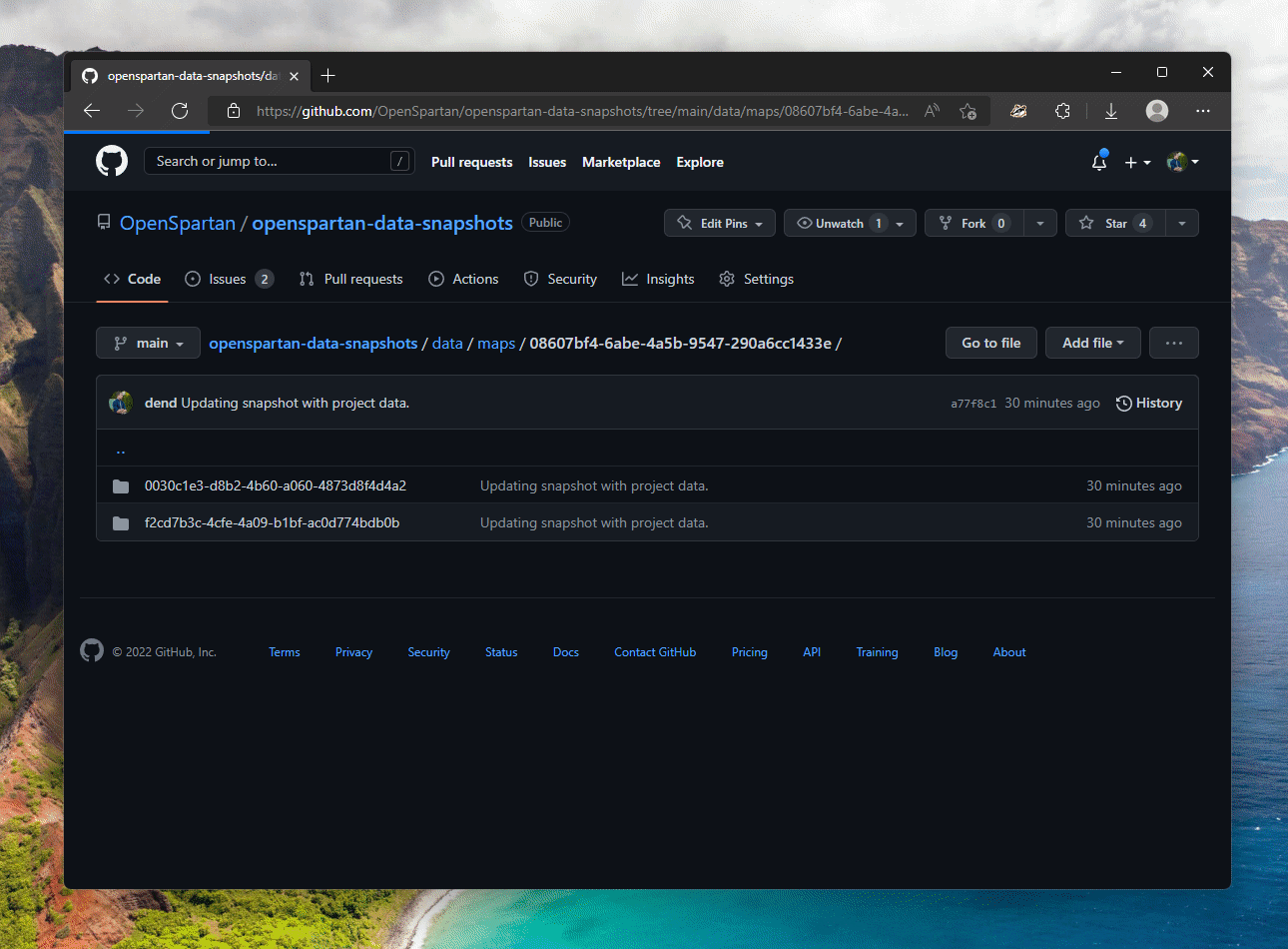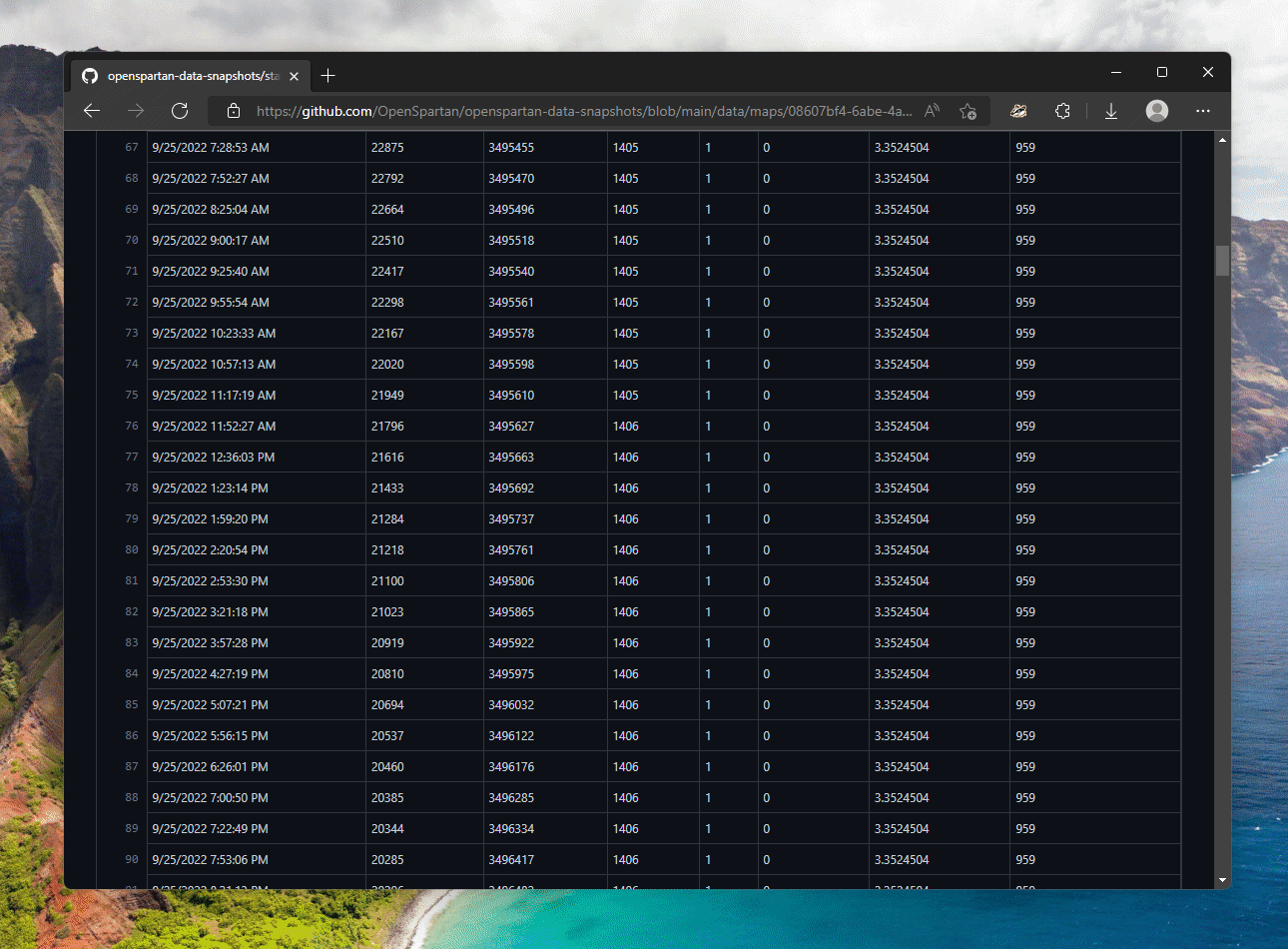
Lastly, the function for asset stats is a bit more convoluted, but that’s only because I wanted one /stats endpoint that returned stats for whatever asset I requested. You can see the implementation in stats.ts. The important bit of code is this:
let assetClass = event.queryStringParameters.class.toLowerCase();
let assetId = event.queryStringParameters.assetId.toLowerCase();
let assetVersion = event.queryStringParameters.assetVersionId.toLowerCase();
let urlClassIdentifier = "";
let data = new GameEntity();
data.stats = new Array<AssetStats>();
switch (assetClass) {
case "map": {
urlClassIdentifier = "maps";
break;
}
case "gamevariant": {
urlClassIdentifier = "game_variants";
break;
}
default: {
urlClassIdentifier = "engine_game_variants";
break;
}
}
I am reading the query parameters passed to the request, and then slightly modifying them to correctly map each to their respective asset folder in GitHub. Once that cleanup is done, I am requesting specific metadata for each asset through a fetch:
await fetch(
`https://raw.githubusercontent.com/OpenSpartan/openspartan-data-snapshots/main/data/${urlClassIdentifier}/${assetId}/${assetVersion}/metadata.json`,
{
method: "GET",
}
).then((r) => {
if (r.ok){
return r.json()
} else {
return null;
}
})
.then((jsonResponse) => {
if (jsonResponse) {
data.name = jsonResponse.Name;
data.description = jsonResponse.Description;
data.heroImageUrl = jsonResponse.HeroImageUrl;
data.thumbnailImageUrl = jsonResponse.ThumbnailImageUrl;
data.versionId = jsonResponse.Version;
}
});
Recall how I mentioned that I can use the https://raw.githubusercontent.com endpoint to get the data I want from public repositories without going through the API - this is it, this is the magic. Once the data is received, it’s stored in a game entity container class. And for the grand finale, I am also requesting the TSV file and using D3.js to fetch it and map the parsed content to the same human-manageable game entity container class:
const d3 = require('d3-fetch');
const tsvData = await d3.dsv("\t", `https://raw.githubusercontent.com/OpenSpartan/openspartan-data-snapshots/main/data/${urlClassIdentifier}/${assetId}/${assetVersion}/stats.tsv`, (d) => {
let stats = new AssetStats();
stats.snapshotTime = d.SnapshotTime;
stats.recentPlays = d.RecentPlays;
stats.allTimePlays = d.AllTimePlays;
stats.favorites = d.Favorites;
stats.likes = d.Likes;
stats.bookmarks = d.Bookmarks;
stats.averageRating = d.AverageRating;
stats.numberOfRatings = d.NumberOfRatings;
data.stats.push(stats);
});
Voila! I now can receive stats for all the different assets that get automatically pulled through my data repository. I can even test the endpoints through Postman if I want to have a fancy response visualization (read: with syntax highlighting):
The endpoints are available to anyone, I am just asking that you be respectful to others and not overload them (GitHub still has an API rate limit, you know) 🤓
- Data for an asset:
https://data.openspartan.com/api/stats?class=enginegamevariant&assetId=042ebf0e-2b4e-4171-bdc7-fe46b1d72a21&assetVersionId=550bd715-e099-4df5-834f-dcbe0b7383d6 - Map data:
https://data.openspartan.com/api/maps - Game variant data:
https://data.openspartan.com/api/gamevariants - Engine game variant data:
https://data.openspartan.com/api/enginegamevariants
In the next implementation, I’ll likely think through ways in which the response can be cached without me round-tripping to GitHub for every call, but that’s for future Den to tackle.