Lessons In Building A Scalable Samples Experience
Table of Contents
You probably heard (or read) a post I wrote back in July about how we built docs.microsoft.com/samples - I talked about some of the foundational elements and the process which we followed to build the site. Now that we’re a couple of months in, I thought I would take a step back and write about some of the lessons learned about shipping the new site, in the hopes that this will be helpful to others who will work on projects of similar scale!
Shipping big things requires n+1 people #
Where n is determined on a case-by-case basis, depending on the project. For the new samples browser, there were so many moving pieces, that it required a dozen half a dozen engineers, plus added partner teams within the company. This would be close to impossible to deliver by working in isolation. We had engineers who built the backend services, others who focused on the frontend, then we had Service Reliability Engineers (aka SREs) who helped set up the Azure services and content partners, that helped ensure that the breadth of existing sample code is covered as the launch was coming up. It was an exciting time to get many people across the spectrum come together and deliver something that is meaningful for developers.
When defining the vision for a project and starting to execute on it, always keep in mind that you will need more than yourself to get it done. Acknowledging that, the question I ask is “How can I remove roadblocks?” - my role is not so much to be the “idea guy” as it is to outline a North Star and remove the friction in delivering the value of the project. Think through what priorities other teams have and try to align yourself with them.
Don’t reinvent the wheel #
The basic requirement for the samples browser was to ensure that we’re not creating something that will then silo us in and reduce our ability to build things developers cared about. Where do developers work with code? On GitHub. Where should the samples be hosted and indexed from? Also GitHub. There is no reason to build some highly-customized experience around a process that will be specific just to us - instead, we focus on delivering maximum value and allow engineers to still get the code the way they are most familiar with, through git clone from a place they already go to. The samples browser is merely an abstraction/convenience layer on top of GitHub content, not a replacement for it.
Rallying people around a common standard is hard #
One of the major additions that we came up with to be able to index the content we actually care about from GitHub was the introduction of YAML front-matter in README.md files for samples that need to be part of the docs.microsoft.com/samples site.
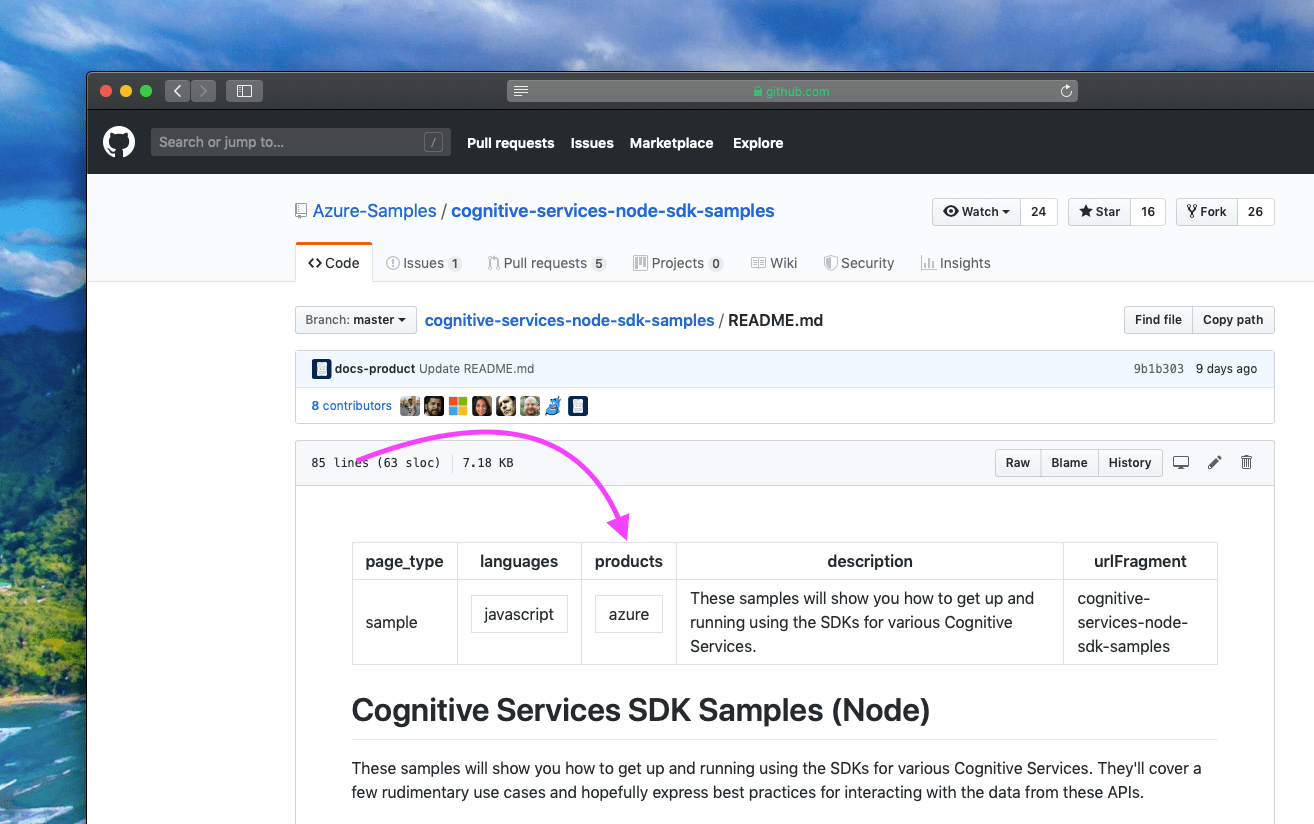
Here is the key problem that we’re addressing - there are a lot of repositories within many organizations of interest, but not all of them need to be considered for ingestion. Some of the repositories are experimental, others are just not samples (there are quite a few that are also no longer supported). In addition to that, we wanted to make sure that we’re able to support an important scenario where one repository can have more than one code sample - we couldn’t treat the repository itself as a standalone sample, even though some of them were. The YAML front-matter in this context offers a degree of control, as it can be integrated in many README.md instances within the repository.
The challenge came with the fact that we needed to get hundreds of repositories across a number of teams and organizations to use the new convention. The reaction we often got is best presented in GIF form.

How do you get many people behind a standard that will make it easier to find their code? There are several approaches that worked well:
- Communicating the benefits. When you come to someone and tell them to change how they do things, there is very little incentive to make those changes without understanding the benefits. On the other hand, everyone likes making their code more discoverable for the audiences they target. A clear outline of the “why” helped a lot in unblocking the path!
- Reducing the amount of work. A lot of different teams have their own priorities and tasks to accomplish. Even with advance notice, we still would need to go against the broader prioritization discussion, which can be even harder than convincing someone of the value of the experience. What helped here is building tooling and collaborating with our content publishing teams to take the load off of our partners’ shoulders and helping them get to the desired destination quicker, with minimal effort. Just let us updated your repositories ourselves!
- Keeping the communication loop going. Another big thing that teams are vary of is change that happens without their input. Keeping partners in the know about what we’re doing, what we’re planning and what we’re changing helps build trust and goodwill when it’s time for the rubber to meet the road. I am personally a big believe in “Communicate often, communicate everything.”
Constant and consistent maintenance is hard #
The experience is out, users start relying on the site to find sample code - what about those that need to now update said code and add new content as it gets released? Someone will be tasked with maintaining the metadata and adding new entries where they are needed, which in itself can be a cumbersome and seemingly tedious process. To solve the issue, we’ve partnered with the Microsoft Open Source Programs Office (shout-out to Jeff Wilcox for all the timely help) to make sure that metadata is added as part of a standard template when repositories are first created.
Whenever anyone at Microsoft provisions a new GitHub repository in one of the company-supported organizations and tags it as a sample, we will automatically provision the right web hook, add placeholder metadata and set up the appropriate user permissions. Our goal is to ensure that we have all the documentation available for partners, and automate as much of the process as possible. When we launched the Minimum Viable Product (MVP) version of the experience, we did not yet have a fully-automated workflow for onboarding a repository - so we wrote a Python script that is able to do literally everything for the sample owner in terms of getting the code into the index in one simple CLI command. Removing friction in maintenance processes is a “must do” if you want to spend time innovating rather than jumping from one fire to the next. And write good documentation!

Here is the reality, though - no matter how many things you write down, there will be a non-zero number of people who will not read the docs (because they might not be aware they exist) or will disregard them altogether because your guidelines aren’t quite aligned with the existing processes (which, in turn, adds friction in priority alignment). This leads me to the next lesson learned.
Enforcing a quality standard requires automation #
When you operate at company-wide scale, it becomes obvious that manual work will not cut it - you will be overwhelmed with requests for support and questions about the infrastructure. That’s where automation comes in.
You can use it both monitoring and fixing issues that cause downstream problems. Here is a recent example - we had a problem where we wanted to ensure that all sample README.md files have just one H1 heading in the file. Without this, the page rendered on docs.microsoft.com might not be as well-formatted. It would be hard to manually check hundreds of repositories over a time period, or just provide the guidelines and hope that everyone will follow them. Instead, we built a minimal monitoring service that scans onboarded repositories and if it identifies header “infractions”, it will automatically correct the README.md by re-calculating the headings within the Markdown source and committing the changes. Problem solved, and no humans were ever involved! That’s the only way to scale your efforts and ensure that you’re able to have time to focus on more important things.
I also want to call out the tremendous effort put into the tooling made by our service engineers. At first, we’ve indexed all samples that had the correct metadata, but we missed an important scenario where metadata could be updated in such a way that it would result in two or even three entries in the samples browser for the same code sample! That’s not something we’d want, so our engineers came up with a creative solution - using the underlying data store to figure out how to adjust the at-rest content in the publishing repository. If the indexer could not process the metadata and removed the entry in the data store, we would also remove the at-rest file from the repository from which the samples browser is built. An elegant automated solution to an otherwise mundane maintenance task - you don’t want to spend time every day hunting for things that should not be in the index, trust me.
Constant iteration is key #
Back in the day, we had these big MSDN Library boxes, that shipped with all the documentation and code samples that you will ever need, for the particular version of Visual Studio that you had installed.

It was thrilling to get one of those, and even more exciting to see it light up on your local machine, in its full MSDN Library glory!
Although the “frozen in time” documentation model might’ve been suitable in 1998, it all changed with online experiences. No user-facing web site is every truly done, no matter how much effort you put in it. This applies to docs.microsoft.com/samples as well. What this means is that no matter how many guidelines you put in place, no matter how well you design the README.md structure to be easily consumable, the user needs evolve and change over time, and it’s going to be up to you to be on top of those and ensure that they’re reflected in the product and the governance around it. The first version of the guidance that we put in place for code samples already went through a number of significant changes - and we’re only two months into having the site live! Be prepared to ship on a continuous basis rather than deliver and move on to the next thing.
And look at how far we’ve come with docs.microsoft.com from the documentation CDs era!
You and partner teams are not the same as your users #
This is probably the most salient point that we knew we needed to consider as we worked through both the components and the guidance around the samples browser - the needs of our users are not the same as those of our partners, so we needed to find a way to balance out the requirements and concerns. One of the things that raised some questions internally was the YAML front-matter - it was new and jarring to some of the engineers that built samples in GitHub, as it was an addition to the README.md file they were not familiar with. However, the added benefit of the YAML front-matter in terms of making the code discoverable and manageable outside of GitHub was outweighing the slight increase in the size of the README.md to the users of the site. Developers out there did not even bother mentioning the metadata because they were so keen to start using the code!
So keep this in mind - balance internal and external concerns, but keep front-and-center the knowledge about who is going to be using the experience, and what is the added value that you’re providing that can justify the trade-offs.
Unexpected things will happen #
Even with careful planning, unexpected things will happen. The very first live experience had a number of bugs that we caught after the release, that affected how we showed the filters and the cards (some of them were rendering HTML where they shouldn’t have) - and that’s totally OK! We identified the bugs, logged them internally, and then one-by-one addressed them. In your plan, add some flex time for these kinds of tasks, and carefully listen to your users - they will often run into scenarios that you couldn’t have predicted at the time when you were writing your specification document!
Simplify, simplify, simplify #
Last but not least, it was important that as we think through the design of the experience and any changes, we stay true to the mission of making it easy for developers to get started with our code. Feature creep is a very real thing, and it’s easy to get excited about a lot of new and shiny things. However, if that doesn’t serve the goals of the experience, that is merely a distraction that takes time and resources away from solving a true customer problem.
Simplification also relates to internal processes. When we think about the automation that we need to put in place, our goal is to make it easy for partner teams to focus on the code and not worry about our system requirements. After all, we can only provide good samples to developers if we get out of the way and let teams do what they do best - write code that other developers will use.